![]() ISSN 0798 1015
ISSN 0798 1015

![]() ISSN 0798 1015
ISSN 0798 1015
Vol. 41 (Nº 07) Año 2020. Pág. 22
BODERO, Elba M. 1; LOPEZ, Milton P. 2; CONGACHA, Ana E. 3; CAJAMARCA, Efren E. 4 y MORALES, Cristian H. 5
Recibido: 13/11/2019 • Aprobado: 14/02/2020 • Publicado 05/03/2020
RESUMEN: Este estudio realizó un análisis del rendimiento de Google Colaboratory en el entrenamiento de una red neuronal convolucional para la clasificación de imágenes. Las pruebas se realizaron con cuatro DataSets, se aplicó un enfoque cuantitativo, una investigación experimental y descriptiva. Se demostró que no existe una diferencia significativa en el tiempo de entrenamiento de la red neuronal en Google Colaboratory y un computador personal, sin embargo, existe una menor pérdida y mayor precisión del modelo en la clasificación de imágenes. |
ABSTRACT: This study performed an analysis of the performance of Google Collaboratory in training a convolutional neural network for image classification. The tests were carried out with four DataSets, a quantitative approach, an experimental and descriptive investigation was applied. It was shown that there is no significant difference in the training time of the neural network in Google Collaboratory and a personal computer, however, there is less loss and greater accuracy of the model in the classification of images. |

La computación en la nube y el machine learning, dos tendencias tecnológicas que en la actualidad están siendo partícipes de un importante cambio en la vida del ser humano, tanto en actividades cotidianas, como en muchos procesos organizacionales de empresas e instituciones a nivel global. Esto sin duda formará parte del desarrollo e innovación a través de un paradigma computacional orientado a facilitar y mejorar la realización de actividades complejas.
La computación en la nube es un entorno basado en Internet que nos permite utilizar software, datos y servicios a través de la red, desde cualquier ubicación mediante un dispositivo habilitado para la web. Esta tecnología tiene una gran flexibilidad, como recursos bajo demanda y disponibilidad de servicios (Hussein & Khalid, 2016). Es ahora una tendencia mundial y durante la última década ha llamado la atención de las comunidades académicas y empresariales (Bayramusta & Nasir, 2016). Además, está produciendo buenos resultados para los clientes debido a que elimina la necesidad de tener una infraestructura completa de software y hardware, para cumplir con los requisitos y aplicaciones de los mismos (Malik, 2018). Es así que también para el procesamiento de aplicaciones o algoritmos complejos pueden aprovecharse los servicios en la nube, los cuales podrían proporcionar características de hardware superiores a los que habitualmente un analista de datos puede tener acceso con un computador personal.
La computación en la nube no se limita a reducir el gasto de capital, sino que también se usa para realizar billones de cómputos por segundo, en aplicaciones orientadas al consumidor, como: carteras financieras para entregar información personalizada, proporcionar almacenamiento de datos o juegos de computadora inmersivos Chawla, et al., (2019).
Por otro lado, la inteligencia artificial es el estudio y desarrollo de máquinas y software inteligentes que pueden razonar, aprender, reunir conocimiento, comunicarse, manipular y percibir los objetos (Pannu, 2015). Machine learning, que aborda la cuestión de cómo construir computadoras que se mejoren automáticamente a través de la experiencia, es uno de los campos técnicos de más rápido crecimiento en la actualidad, ubicado en la intersección de la informática y las estadísticas, en el núcleo de la inteligencia artificial y la ciencia de datos (Jordan & Mitchell, 2015). Las técnicas basadas en el aprendizaje automático se han aplicado con éxito en diversos campos que van desde el reconocimiento de patrones, visión por computadora, ingeniería de naves espaciales, finanzas, entretenimiento, biología computacional, hasta aplicaciones biomédicas y médicas (Naqa & Murphy, 2015). Deep Learning es un tipo de machine learning que permite a los modelos computacionales compuestos de múltiples capas de procesamiento, aprender representaciones de datos con múltiples niveles de abstracción. Estos métodos han mejorado dramáticamente el estado del arte en reconocimiento de voz, reconocimiento de objetos visuales, detección de objetos y muchos otros dominios como el descubrimiento de fármacos y la genómica. El aprendizaje automático descubre una estructura compleja en grandes conjuntos de datos mediante el uso del algoritmo de retropropagación para indicar cómo una máquina debe cambiar sus parámetros internos que se utilizan para calcular la representación en cada capa a partir de la representación en la capa anterior (LeCun, Bengio, & Hinton, 2015).
Las redes neuronales artificiales (ANN) son un subcampo del aprendizaje automático dentro del dominio de investigación de la inteligencia artificial. El objetivo de la investigación de ANN es desarrollar sistemas de aprendizaje automático basados en un modelo biológico del cerebro, específicamente la actividad bioeléctrica de las neuronas en el cerebro (Walczak, 2019).
Para entender las redes neuronales convolucionales es necesario comprender que la convolución es una operación matemática, en la que una función se "aplica" a otra función, el resultado se puede entender como una "mezcla" de las dos funciones, las convoluciones son realmente buenas para detectar estructuras sencillas de una imagen, y esas sencillas funciones juntas, permiten construir funciones aún más complejas. En una red convolucional, este proceso ocurre sobre una serie de muchas capas, en la que cada una de ellas realiza una convolución sobre el resultado de la capa anterior (IBM, 2018).
En muchas ocasiones los algoritmos de machine learning, junto con una gran cantidad de datos dificultan la obtención de resultados en corto tiempo, debido a que el tiempo de procesamiento es elevado y los computadores convencionales no soportan esta carga. En este contexto es posible aprovechar las bondades de la computación en la nube.
Google Colaboratory (también conocido como Colab) es un servicio en la nube basado en Jupyter Notebooks para difundir la educación y la investigación del aprendizaje automático. Proporciona un tiempo de ejecución totalmente configurado para el aprendizaje profundo y el acceso gratuito a una GPU robusta (Carneiro et al., 2018).
Este trabajo de investigación tiene por objetivo analizar el rendimiento del servicio de Google Colaboratory, frente al procesamiento en un computador convencional o personal, al clasificar cuatro grandes conjuntos de datos de imágenes, aplicando un algoritmo basado en redes neuronales convolucionales, con la finalidad de presentar una alternativa para ejecutar aplicaciones de machine learning en un tiempo menor con resultados similares o incluso mejores.
Con respecto a los trabajos relacionados con la presente investigación existen un sin número de estudios científicos de inteligencia artificial los cuales se siguen incrementado en gran medida. Según la Organización Mundial de Propiedad Intelectual (2019) en la primera publicación de la serie de la OMPI "Tendencias de la tecnología" se cuantifican más de 340.000 solicitudes de patente y 1,6 millones de documentos científicos publicados desde el decenio de 1950. En este informe también se detallan las técnicas aplicadas en las innovaciones de inteligencia artificial. El machine learning, en particular, las redes neuronales que han revolucionado la traducción automática, representan más de un tercio de todas las invenciones identificadas. El Deep Learning, por su parte está revolucionando la Inteligencia Artificial con sistemas de reconocimiento de voz y de imágenes. Así también los trabajos científicos relacionados a computación en la nube que se encuentran en los repositorios científicos, son incuantificables, variando en estudios relacionados a los servicios que presta esta tecnología, así como nuevas innovaciones de software disponible para los usuarios.
Relacionado con el reconocimiento de imágenes haciendo uso de machine learning con procesamiento en la nube se presentan varios artículos de los cuales en esta investigación se destacan:
“Evaluación del rendimiento de una aplicación Cloud para un clasificador neuronal aplicado a imágenes hiperespectrales”, el estudio se centra en el rendimiento computacional de una implementación en la nube utilizando Apache Spark, orientada a la clasificación de datos hiperespectrales. Los resultados de esta investigación sugieren que las arquitecturas distribuidas en la nube permiten procesar de forma distribuida grandes conjuntos de datos (Haut, et al., 2016).
“Implementation of design patterns for the optimization of mass load algorithm in cloud computing”, esta investigación tiene como objetivo analizar como el uso de patrones de diseño en los algoritmos de carga masiva puede impactar en el rendimiento de un servicio de computación en la nube. Los resultados indican que el tiempo de respuesta fue disminuyendo a medida que fueron implementados los diseños de patrones en el código del sistema (Castillo & Guerrero, 2017).
“Image Reconstruction is a New Frontier of Machine Learning”, se centra en el estudio de imágenes médicas a través de la aplicación de técnicas de Deep Learning, esta investigación realiza una reconstrucción tomográfica basada en datos, generando lecturas de diagnóstico (Wang, Ye, Mueller, & Fessler, 2018).
“Going Deeper with Convolutions”, se propone una arquitectura de red neuronal convolucional profunda. El sello distintivo principal de esta arquitectura es la utilización mejorada de los recursos informáticos dentro de la red convolucional a través de un diseño innovador (Szegedy et al., 2015).
“Prediction of optical specifications through ANN model to design a monochromatic optical filter for all three optical Windows” es otro. En este trabajo se propone una técnica de aprendizaje automático que utiliza el algoritmo ANN para establecer un modelo para la selección del espesor de Si y SiO. El modelo ANN se desarrolla en Google Colab utilizando el marco TensorFlow que Google proporciona para implementar el algoritmo de aprendizaje automático (Swain, Nayyar, & Palai, 2019).
“Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications”, este documento presenta un análisis detallado de Google Colaboratory con respecto a los recursos de hardware, el rendimiento y las limitaciones. Los casos de prueba elegidos son una búsqueda combinatoria paralela basada en árboles y dos aplicaciones de visión por computadora: detección, clasificación de objetos, localización y segmentación de objetos. El hardware en tiempo de ejecución acelerado se compara con una estación de trabajo convencional y un servidor Linux robusto equipado con 20 núcleos físicos. Los resultados muestran que el rendimiento alcanzado con este servicio en la nube es equivalente al rendimiento de los bancos de pruebas dedicados, dados recursos similares. Finalmente, se discuten varias fortalezas y limitaciones de este servicio en la nube, que podrían ser útiles para ayudar a los usuarios potenciales (Carneiro et al. 2018).
Los trabajos encontrados, se basan en la aplicación de la inteligencia artificial principalmente Deep learning aplicado en varias áreas, existiendo investigaciones en el ámbito del reconocimiento de imágenes y en grandes cantidades de datos. Además existen trabajos que se centran en medir el rendimiento las aplicaciones de machine learning en entornos en la nube. Sin embargo, no se presenta la aplicación del entorno de Google Colaboratory para el entrenamiento de una red neuronal convolucional, a excepción del último artículo descrito el cual proporciona una base útil para realizar esta investigación, diferenciándose de este trabajo, que para esta investigación se utilizó para contrastar los resultados, un entorno convencional de un computador personal, diferentes casos de estudio y el tiempo de la herramienta en el mercado puede influir a obtener diferentes resultados debido a que Google Colaboratory se encuentra más difundida, pudiendo influir el número de usuarios en el rendimiento de la herramienta.
En esta sección se describe la metodología de la presente investigación, la cual tuvo un enfoque cuantitativo debido a que es secuencial y probatoria, con datos que son representados en forma de números y fueron analizados estadísticamente, se sigue un orden que se detalla a continuación (Hernández Sampieri, 2008):
La Tabla 1, presenta las fuentes de datos recolectadas para realizar esta investigación:
Tabla 1
Fuentes de datos de imágenes
N° |
Descripción DataSet Imágenes |
Fuente |
Resolución |
1 |
Deportes: Imágenes pertenecientes a los deportes más populares clasificados en 9 grupos. |
Independiente (aprendemachinelearning.com) |
28x21 px |
2 |
Flores: Imágenes de distintas flores y rosas clasificados en cinco grupos. |
Matlab DataSet Example |
60x60 px |
3 |
Cars: Imágenes de vehículos basados en el DataSet del Laboratorio de Inteligencia Artificial de la Universidad de Stanford, clasificados en cuatro grupos. |
Laboratorio de Inteligencia Artificial de la Universidad de Stanford |
60x60 px |
4 |
Vehículos: DataSet con imágenes de vehículos y principalmente carreteras clasificados en 8 grupos |
Grupo de Tratamiento de Imágenes de la Universidad Politécnica de Madrid |
60x60 px |
Fuente: Elaboración Propia
Una vez que las imágenes fueron recolectadas se realizó la importación de librerías, se cargaron las imágenes en memoria, se crearon las etiquetas para la clasificación de los resultados, se dividieron en sets de entrenamiento y testeo, se realizó el preprocesamiento de los datos, se creó el modelo de la red neuronal convolucional, se entrenó el modelo y se analizaron los resultados obtenidos de la evaluación a la red. Este procedimiento se realizó para los cuatro DataSets. Se capturaron un total de 24 valores de tiempo del entrenamiento para el Computador Personal como para el entorno en Google Colaboratory. Finalmente, a estos resultados se aplicó una prueba estadística para comprobar si existe diferencia significativa en el tiempo de entrenamiento para reconocimiento de imágenes.
Se realizó una descripción de las premisas encontradas durante esta investigación en forma de conclusiones.
los DataSets de los diferentes repositorios, una vez obtenidosl permitieron realizar el experimento de esta investigación. En la Figura 1. se presenta el número de imágenes por cada uno de los DataSets. Se puede observar que el DataSet de “Deportes” es el que presenta un mayor número de archivos seguido por el de “Cars”, “Vehículos” y finalmente el de “Flores.
Figura 1
DataSets de Imágenes
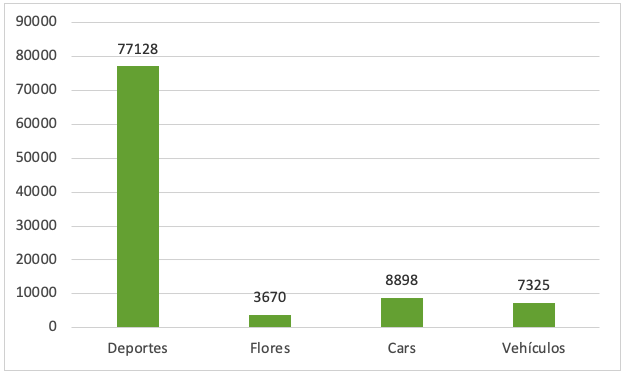
Fuente: Elaboración Propia
En la Figura 2 se muestra un ejemplo de la creación de los sets de entrenamiento y testing, que se realizó una vez que las imágenes fueron cargadas en memoria en los entornos de machine learning, tanto de Google Colaboratory, como el de Jupyter en el computador personal. Además, se realizó un procedimiento denominado “One-Hot encoding”, que trata de convertir las clases en una nueva variable binaria para cada valor entero único.
Figura 2
Sets creados para entrenamiento
y para pruebas del DataSet “Cars”
Fuente: Elaboración Propia
En la Figura 3. se presentan los tiempos totales medidos en segundos, que ha consumido cada uno de los entornos de machine learning, para el entrenamiento de la red neuronal convolucional. Se puede observar que tanto en el DataSet de imágenes “Cars”, “Deportes” y “Flores” el tiempo de Google Colaboratory es superior al del Computador personal a excepción de los datos de “Vehículos” en el cual el tiempo del computador personal es mayor.
Figura 3
Total de tiempos de entrenamiento de
los entornos de machine learning
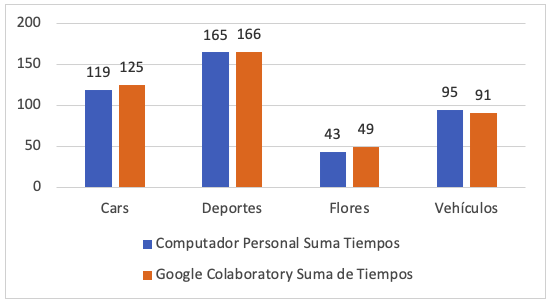
Fuente: Elaboración Propia
En la Figura 4. se pueden observar los promedios medidos en segundos, que tardó cada entorno de machine learning, tanto en el DataSet de “Cars”, como en el de “Flores”, el entorno en la nube de Google Colaboratory presentó un tiempo mayor, en relación al procesado en el computador personal; en contraste en el DataSet de “Vehículos”, en el cual el tiempo en el computador personal supera al de Google Colaboratory. Finalmente, en los datos que corresponden a “Deportes” el promedio de tiempo de entrenamiento de la red neuronal, se presentó con el mismo valor en los dos entornos.
Figura 4
Promedio de tiempos de entrenamiento
de los entornos de machine learning

Fuente: Elaboración Propia
Mediante la utilización del software SPSS se realizó una estadística descriptiva la cual proporcionó una media de tiempo de procesamiento de 17,96 segundos para Google Colaboratory y de 17,58 segundos para Jupyter en el Computador Personal, existiendo muy poca diferencia entre estos valores. Para la comprobación de la hipótesis, en primera instancia se pretendió utilizar la prueba de T Student por tratarse de muestras independientes. Sin embargo, como se puede observar en la Tabla 2, en la prueba de Shapiro Wilk, que fue utilizada por tratarse de una muestra pequeña, el valor encontrado no es menor a 0,05 para cumplir con el principio de normalidad, por cual fue necesario la utilización de una prueba no paramétrica, como la de Mann-Whitney.
Tabla 2
Prueba de normalidad
de Shapiro-Wilk
Promedio Train |
,998 |
4 |
,993 |
|
PC |
,997 |
4 |
,990 |
Fuente: Elaboración Propia
Hipótesis Nula (H0): No existe diferencia entre los tiempos de entrenamiento de la red neuronal convolucional al realizar el procesamiento con el entorno Jupyter del computador personal y con el entorno en la nube Google Colaboratory.
Hipótesis Alternativa (H1): El tiempo de entrenamiento al realizar el procesamiento de la red neuronal convolucional con el entorno Jupyter del computador personal es mayor al tiempo de entrenamiento de esta red utilizando el entorno en la nube Google Colaboratory.
Tabla 3
Estadísticos de prueba
Mann-Whitney
U de Mann-Whitney |
265,00 |
W de Wilcoxon |
565,00 |
Z |
-,477 |
Sig. asintótica (bilateral) |
,633 |
a. Variable de agrupación: Grupo |
|
Fuente: Elaboración Propia
El valor de la Sig. asintótica (bilateral) no es menor a 0,05 rechazando la hipótesis alternativa y aceptando la hipótesis nula la cual menciona que “No existe diferencia entre los tiempos de entrenamiento de la red neuronal convolucional al realizar el procesamiento con el entorno Jupyter del computador personal y con el entorno en la nube Google Colaboratory”.
En la Tabla 4. se detallan los valores del testeo de pérdida y de precisión, que se presentaron en la etapa de evaluación de la red neuronal convolucional, una vez que el modelo ha sido entrenado y haya aprendido a clasificar las imágenes. Se puede apreciar que en el entorno en la nube de Google Colaboratory, todos los DataSets arrojan resultados menores en pérdida y mayores en precisión que el entorno Jupyter del computador personal, a pesar de haber utilizado el mismo algoritmo de machine learning. Cuanto menor sea la pérdida mejor será un modelo, en las redes neuronales el testeo de pérdida suele ser una probabilidad logarítmica negativa y una suma residual de cuadrados para la clasificación, a diferencia de la precisión, la pérdida no representa un porcentaje. Es más bien un resumen de los errores que cada conjunto de datos de entrenamiento presenta en su fase de validación.
Tabla 4
Fuentes de datos de imágenes
|
Computador Personal |
Google Colaboratory |
||
DataSet |
Testeo Pérdida |
Testeo Precisión |
Testeo Pérdida |
Testeo Precisión |
Deportes |
0,76 |
0,81 |
0,64 |
0,85 |
Flores |
1,42 |
0,41 |
1,27 |
0,47 |
Cars |
1,27 |
0,40 |
1,25 |
0,42 |
Vehículos |
2,07 |
0,12 |
2.06 |
0.14 |
Fuente: Elaboración Propia
La computación en la nube presenta alternativas tecnológicas que permiten proporcionar servicios de procesamiento y datos, que junto al progreso reciente en el aprendizaje automático ha impulsado la aplicación de estas dos tecnologías en diferentes sectores de la industria y ha generado varias investigaciones en busca de la mejora continua de las mismas.
En contraste a los estudios encontrados descritos en esta investigación y una vez realizadas las pruebas con los cuatro DataSets de imágenes, aplicando la prueba no paramétrica de Mann-Whitney, se pudo determinar que el servicio en la nube de Google Colaboratory, no presenta una diferencia estadística significativa en el tiempo de procesamiento en la fase de entrenamiento de una red neuronal convolucional, frente a un computador personal con las características de hardware y software que se detallan en este documento. Varios factores pueden provocar que este dato haya cambiado, por ejemplo, el incremento del número de usuarios que procesan sus algoritmos de machine learning en Google Colaboratory, pudo variar el rendimiento de este entorno. Además, pueden haberse establecido en la empresa Google, políticas internas de procesamiento de esta herramienta, asignando a una cuenta un menor recurso de hardware.
La clasificación de imágenes realizada a los cuatro DataSets de prueba también ha permitido identificar ciertas diferencias entre los dos entornos, en donde se ha podido identificar un testeo en pérdida menor y una precisión mayor en el entorno en la nube Google Colaboratory, lo cual puede permitir decantar a un analista de datos por esta herramienta, en lugar de utilizar el entorno Jupyter de un computador personal.
En futuros trabajos se buscará comprobar el rendimiento de la plataforma de Google Colaboratory no solo en su fase de entrenamiento, sino, además, la medición del tiempo completo para la ejecución del algoritmo, que implica desde la importación de librerías, la carga de imágenes y la ejecución de todos los procedimientos. Esto debido a que durante esta investigación se ha podido identificar que esta plataforma en la nube realiza estas actividades en menor tiempo que un computador personal. Además, es necesario realizar pruebas con DataSets de imágenes con una mayor resolución, con la finalidad de determinar si con una carga mayor existen resultados diferentes a los expuestos en esta investigación.
Bayramusta, M., & Nasir, V. A. (2016). A fad or future of IT?: A comprehensive literature review on the cloud computing research. International Journal of Information Management, 36(4), 635-644.
Carneiro, T., Da Nóbrega, R. V. M., Nepomuceno, T., Bian, G. B., De Albuquerque, V. H. C., & Reboucas Filho, P. P. (2018). Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access, 6, 61677-61685.
Carneiro, T., Da Nóbrega, R. V. M., Nepomuceno, T., Bian, G. B., De Albuquerque, V. H. C., & Reboucas Filho, P. P. (2018). Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access, 6, 61677-61685.
Castillo, J. Á. P., & Guerrero, F. T. (2017). Implementación de patrones de diseño para la optimización de algoritmo de carga masiva en computación en la nube Implementation of design patterns for the optimization of mass load algorithm in cloud computing. Daena: International Journal of Good Conscience, 12(3), 423-428.
Chawla, P., Jha, S., Saxena, R., & Shakya, I. (2019). Perspectives of Cloud Computing Management: An Overview. Journal of Computer Technology & Applications, 6(3), 72-82.
El Naqa, I., & Murphy, M. J. (2015). What is machine learning?. In Machine Learning in Radiation Oncology (pp. 3-11). Springer, Cham.
Haut, J. M., Paoletti, M., Plaza, J., & Plaza, A. (2016). Evaluación del rendimiento de una implementación Cloud para un clasificador neuronal aplicado a imágenes hiperespectrales. Actas Jornadas Sarteco, 127-134.
Herández, R. (2008). Metodología de la Investigación. México: McGraw-Hill.
Hussein, N. H., & Khalid, A. (2016). A survey of cloud computing security challenges and solutions. International Journal of Computer Science and Information Security, 14(1), 52.
IBM. (07 de 12 de 2018). Página Oficial de IBM. Obtenido de https://www.ibm.com/developerworks/ssa/library/cc-convolutional-neural-network-vision-recognition/index.html
Jordan, M. I., & Mitchell, T. M. (2015). Machine learning: Trends, perspectives, and prospects. Science, 349(6245), 255-260.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. nature, 521(7553), 436-444.
Malik, Mohammad Ilyas. (2018). CLOUD COMPUTING-TECHNOLOGIES. International Journal of Advanced Research in Computer Science. 9. 379-384. 10.26483/ijarcs.v9i2.5760.
Organización Mundial de la Propiedad Intelectual. (31 de 01 de 2019). Sitio Oficial de la OMPI. Obtenido de https://www.wipo.int/pressroom/es/articles/2019/article_0001.html
Pannu, A. (2015). Artificial intelligence and its application in different areas. Artificial Intelligence, 4(10), 79-84.
Swain, K. P., Nayyar, A., & Palai, G. (2019). Prediction of optical specifications through ANN model to design a monochromatic optical filter for all three optical windows. Optik, 198, 163314.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., ... & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
Walczak, S. (2019). Artificial neural networks. In Advanced Methodologies and Technologies in Artificial Intelligence, Computer Simulation, and Human-Computer Interaction (pp. 40-53). IGI
Wang, G., Ye, J. C., Mueller, K., & Fessler, J. A. (2018). Image reconstruction is a new frontier of machine learning. IEEE transactions on medical imaging, 37(6), 1289-1296.
1. Mgs. en Tecnología de la Información y Multimedia Educativa. Docente de la Universidad Nacional de Chimborazo. ebodero@unach.edu.ec
2. Mgs. en Gerencia Informática, MBA. Docente de la Universidad Nacional de Chimborazo. milton.lopez@unach.edu.ec
3. Mgs. en Gerencia Informática. Docente de la Universidad Nacional de Chimborazo. acongacha@unach.edu.ec
4. Ing. en Sistemas y Computación. Analista de Investigación de la Universidad Nacional de Chimborazo. ecajamarca@unach.edu.ec
5. Mgs. en Gestión de Sistemas de Información e Inteligencia de Negocios, EMBA. Editor Sprint Publications, Presidente Agricommerce Cia. Ltda. cristianmorales18m@gmail.com
[Índice]
revistaespacios.com

Esta obra está bajo una licencia de Creative Commons
Reconocimiento-NoComercial 4.0 Internacional