 HOME | ÍNDICE POR TÍTULO | NORMAS PUBLICACIÓN
HOME | ÍNDICE POR TÍTULO | NORMAS PUBLICACIÓN Espacios. Vol. 37 (Nº 05) Año 2016. Pág. 23
Bruno Samways dos SANTOS 1, Maria Teresinha Arns STEINER 2, Luis Henrique de Lara RAMOS 3; Luis Guilherme Ribeiro MARTINS 4; Pedro Rochavetz de Lara ANDRADE 5
Recibido: 10/10/15 • Aprobado: 03/11/2015
4. Levantamento das aplicações
RESUMO: O presente artigo tem o objetivo de apresentar conceitos, técnicas e aplicações do data mining em diversas áreas. Foram feitas buscas em bases de dados para a identificação de tais características e resumidas em um quadro, este contendo o nome dos autores e ano de publicação, objetivo e técnicas, linguagem e software e resultados obtidos. Verificou-se que os autores utilizaram mais significativamente a técnica de árvores de decisão e teve uma maior aplicação nas áreas industriais e de saúde. |
ABSTRACT: This paper aims to present concepts, techniques and applications of data mining in several areas. Searches in databases have been made to identify and summarize their characteristics, containing the names of authors and year of publication, objective and technique applied, programming language and areas and software and results. It was verified the authors used most significantly the decision tree technique and applied de data mining on industry, health and education. |
Atualmente, a grande quantidade de dados armazenados em qualquer tipo de organização, como bancos, indústrias, serviços de transporte e hospitalares, entre outros, é fonte de informação muitas vezes não percebida pelos usuários destes sistemas. As técnicas e ferramentas que buscam transformar estes dados em conhecimento propriamente dito é o objetivo da área denominada Descoberta de Conhecimentos em Bases de Dados (Knowledge Discovery in Databases – KDD) (Steiner et al., 2006).
O KDD consiste no amplo processo de descoberta de informações em banco de dados. Este processo identifica padrões de dados válidos de maneira não-trivial, transformando-os em dados possivelmente úteis e interpretáveis (Tronchoni et al., 2010). O KDD é importante para a tomada de decisão uma vez que permite a aplicação de técnicas para auxiliar em todo o processo de descobrimento de dados, as quais eram inicialmente aplicadas para fins comerciais apenas (Carvalho et al., 2012). Para Freitas (2000) o conhecimento a ser descoberto deve satisfazer três propriedades: ser o mais correto possível; ser compreensível; e ser interessante/útil/novo. Segundo Fayyad et al. (1996), o KDD é um conjunto composto, basicamente, por 5 atividades contínuas e sequenciais com relação aos dados: seleção; pré-processamento e limpeza; transformação; mineração dos dados (ou data mining; DM ou, ainda, Big Data) e interpretação dos resultados (Figura 1).
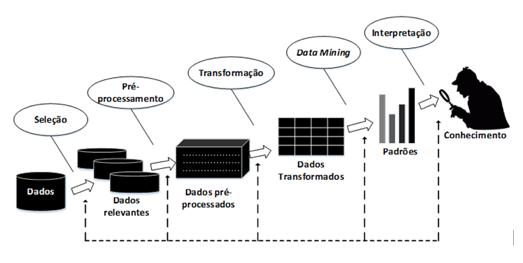
Figura 1 – Conjunto de atividades do KDD
Fonte: Adaptado de Fayyad et al. (1996)
As etapas de seleção, pré-processamento e transformação fazem parte de uma macro-etapa chamada "análise de dados". Esta análise é necessária para identificar os dados relevantes para a descoberta de conhecimento, incluindo a padronização dos mesmos (por exemplo, unidades de medida) e a eliminação daqueles que possam interferir na aplicação de algoritmos de mineração de dados ou para tomada de decisão. Desta forma, é importante a seleção criteriosa dos dados para reformular o banco de dados e descartar aqueles que não agregam ou tenham sido colocados em uma planilha de forma equivocada.
Para a análise de dados, vários algoritmos e procedimentos podem ser utilizados para selecionar aqueles que realmente gerarão conhecimento, dentre os quais podem ser citados:
O objetivo do presente artigo é apresentar conceitos e técnicas relacionadas à etapa de DM em conjunto com algumas aplicações apresentadas na literatura, observando-se as áreas em que foram apliacadas, algoritmos e técnicas abordadas. A seção 2 conceitua DM explicando seus objetivos. A seção 3 especifica algumas técnicas que têm sido utilizadas e algumas aplicações em estudos anteriores (seção 4). A seção 5 complementa os estudo com as devidas considerações.
De acordo com Tan, Steinbach e Kumar (2009), DM é o processo de descoberta de informações úteis em grandes quantidades de dados. Pode-se afirmar então que não é necessário tratar manualmente dados de diferentes origens para a tomada de decisão, pois algumas técnicas matemáticas e computacionais específicas podem realizar esta tarefa com uma precisão significativa. Como complemento, DM pode ser definido como o processo para descobrir "padrões" nos dados (WITTEN; FRANK, 2005).
PhridviRaja e GuruRao (2014) ressaltam a diferença entre os dados em uma base de dados (database) e em um armazém de dados (data warehouse), sendo que no primeiro, os dados estão em formato estruturado enquanto que no segundo não necessariamente. Para a utilização das técnicas de DM, os dados devem estar previamente estruturados para processamento.
A mineração de dados pode ser utilizada em diferentes situações que dependem do objetivo da aplicação: classificação e previsão; associação; análise de grupos (ou clusterização) (TAN; STEINBACH; KUMAR, 2009).
Na previsão, pode-se pensar que existe um conjunto de atributos xi o qual é inserido dentro de um modelo de classificação para se obter um rótulo ou identificação de saída y. Por exemplo, Yap, Ong e Husain (2011) aplicaram na área de concessão de crédito em banco, assumindo que a partir de alguns atributos (indicadores demográficos, emprego, dentre outros) pode-se classificar novos pedidos de crédito, julgando-os se seria ou não interessante conceder crédito. A previsão pode ser executada para a classificação (variáveis alvo discretas) ou regressão (variáveis alvo contínuas).
Usa-se a associação de dados para descrever características com alto grau de "correlação" no conjunto de padrões a serem reconhecidos em um conjunto de dados. Esta pode ser exemplificada com o cotidiano de compras dentro de um supermercado, pois pode-se conseguir com o histórico de compras por parte dos clientes, obtendo-se algumas associações como: homens que compram cerveja quase sempre compram petiscos ou, ciranças que compram chocolate quase sempre compram refrigerante. Desta forma, os gestores podem arranjar fisicamente estes produtos de forma que eles fiquem próximos, aumentando as chances de vendas destes produtos.
Esta análise tem o objetivo de encontrar grupos de observações intimamente relacionadas de modo que observações dentro de um grupo tenham uma semelhança mais acentuada quando comparadas a outros grupos (HAN; KAMBER, 2001; TAN; STEINBACH; KUMAR, 2009). Esta análise pode separar notícias de um jornal em dois grupos baseado em suas palavras mais repetitivas como, por exemplo, um grupo que contenha artigos relacionados à culinária e outro que seja da área de construção civil.
De acordo com Lemos, Steiner e Nievola (2005), DM pode ser utilizada para a solução em diversas áreas:
Existe a influência de diversas áreas na busca por informações que sejam úteis de fato comprovando, desta forma, que DM é uma área de pesquisa multidiscplinar que inclui tecnologias de bancos de dados, estatística, inteligência artificial, reconhecimento de padrões, sistemas baseados em conhecimento, visualização de dados e computação de alto desempenho (CARDOSO; MACHADO, 2008).
A descoberta de conhecimento se dá por meio da utilização de diversas técnicas, algumas delas conceituadas e explicadas no capítulo 3.
Como já citado anteriormente, para a obtenção das informações a partir de um banco de dados é necessária a aplicação de técnicas de DM. Muitas técnicas e aplicações de DM podem ser encontradas na literatura, algumas mais recentes, outras mais antigas, porém, não menos importantes.
Várias são as técnicas, dentre as quais, têm-se:
A PL extensivamente utilizada em problemas de otimização, propriamente ditos, possui aplicação em DM também. Bennett e Mangasarian, 1992, apresentaram um modelo matemático de PL que tem como objetivo minimizar a média ponderada da soma das violações de dois conjuntos dados (A e B) que estão do lado errado de um plano separador. Com isso, procura-se gerar um plano que minimiza erros quando as coberturas convexas de dois conjuntos se interceptam e de modo não iterativo. O modelo matemático para esta técnica está apresentado de (1)-(5), a seguir:

A ilustração geométrica para esta técnica que faz uso da PL está na Figura 2.
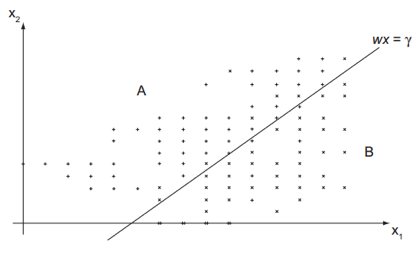
Figura 2 – Ilustração do método que faz uso da PL.
Fonte: Steiner et al. (2006)
A Figura 2 mostra um exemplo para um conjunto com dois atributos (x1 e x2), com 99 dados os quais estão distribuídos em A = 53 e B = 46, como o plano separador ótimo w*x = γ.
A partir de duas amostras A e B de observações multivariadas xi ![]() Rn, Fisher transformou estas em observações univariadas Y's, de tal modo que sejam separadas tanto quanto possível. Para Oliveira, Steiner e Costa (2012), o método é de fácil cálculo e sua função discriminante otimiza a alocação de novos padrões). A função discriminante linear de Fisher amostral é dada pela equação (6).
Rn, Fisher transformou estas em observações univariadas Y's, de tal modo que sejam separadas tanto quanto possível. Para Oliveira, Steiner e Costa (2012), o método é de fácil cálculo e sua função discriminante otimiza a alocação de novos padrões). A função discriminante linear de Fisher amostral é dada pela equação (6).
![]()

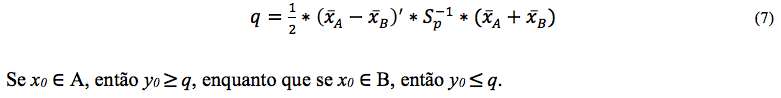
Yap, Ong e Hussain (2011) citam que a RL é um modelo estatístico bastante utilizado quando existe uma saída probabilística dicotômica (Y=0 ou Y=1). O modelo pode ser descrito por (8).
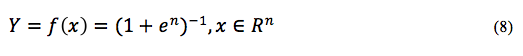
Com a equação (8) estima-se Y usando uma função matemática sigmoidal (logística), com n=g(x) obtido em um ajuste linear obtida por uma função desvio sp que é o valor da matriz de covariância entre os conjuntos A e B.
De acordo com Yao, Ong e Hussain (2011), um modelo de AD consiste em um conjunto de regras para a divisão de uma grande quantidade de observações em grupos menores e homogêneos. Pode ser apliccada tanto para variáveis dicotômicas como contínuas, entretanto, sua grande vantagem é a utilização de variáveis categóricas, o que facilita a interpretação dos gestores quanto aos seus resultados. Steiner et al. (2006) mostram que a estratégia de uma AD é dividir-para-conquistar representando as regras em conjuntos do tipo SE-ENTÃO (IF-THEN). Alguns dos algoritmos mais aplicados para as AD são: ID3 e C4.5 (NGAI; XIU; CHAU, 2009). Uma ilustração geométrica de uma AD é apresentada na Figura 3.
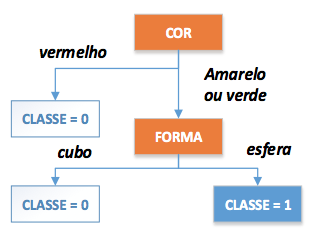
Figura 3 – Conjunto de atividades do KDD
Fonte: Adaptado de Fayyad et al. (1996)
A Figura 3 gera, por sua vez, três regras de classificação:
Se(cor=vermelho) Então Classe=0 Se (cor=amarelo ou verde) e (forma=cubo) Então Classe=0 Caso contrário Então Classe=1 |
As RNA são amplamente utilizadas em problemas de DM. Esta técnica tenta construir representações internas de modelos ou padrões detectados nos dados que não são visíveis para os usuários (LEMOS; STEINER; NIEVOLA, 2005; MENDES; FIUZA; STEINER, 2010). Existem várias tipos de redes neurais, porém a mais utilizada é a MultiLayer Perceptron (MLP). Para Kusiak, Zeng e Zhang (2013), uma rede MLP consiste em múltiplas camadas de nós representando um grafo no qual os nós da camada anterior são conectados diretamente a todos os nós da camada posterior, como representado na Figura 4.
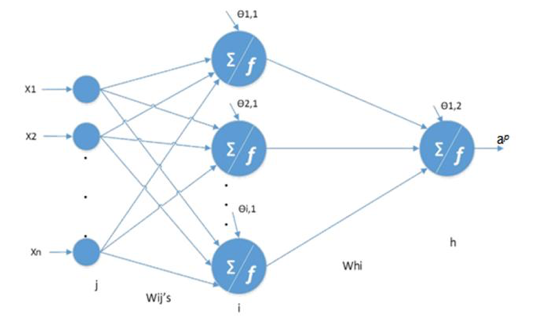
Figura 4 – Representação de uma rede neural com camadas de entrada escondida e de saída.
Fonte: Autores (2015)
Para a rede da Figura 4 é utilizado um algoritmo de aprendizagem chamado back-propagation, um dos mais utilizados para o ajuste do conjunto de pesos W a partir dos atributos xi e com as saídas das classes conhecidas. O número de neurônios da camada de entrada é o mesmo número de atributos considerados, enquanto que os neurônios das camadas de saída e escondida devem ser estabelecidos pelo analista/gestor.
Na procura dos artigos relacionados com o DM, destacam-se as base de dados do Scielo, Portal Capes e Science Direct, buscando termos como "data mining", "mineração de dados" e "big data".
Para ilustrar a disseminação no uso de DM nas mais diversas áreas, o Quadro 1 a seguir traz uma relação de artigos com a aplicação prática destas técnicas. O levantamento buscou identificar a aplicação quanto ao seu objetivo, área, softwares utilizados e resultados obtidos.
AUTORES (ANO) |
ÁREA |
OBJETIVO |
LINGUAGEM/SOFTWARE |
RESULTADOS |
Horta e Alves (2012) |
Financeira |
Identificar atributos que influenciam a decisão de estrutura de capital empregando-se dados de empresas brasileiras, não financeiras, de capital aberto, através da comparação das abordagens Wrapper, ACP e Abordagem Filtro. |
WEKA |
Os resultados sugerem que as variáveis explicativas das estratégias de crescimento financeiro são: setor econômico, retorno dos acionistas, rentabilidade sobre o ativo total, liquidez imediata, liquidez geral e giro do ativo. |
Lazzaroto, Oliveira e Lazzaroto (2006) |
Agropecuária |
Avaliar a qualidade de previsões de preços agropecuários, obtidas com o emprego das RNA. |
MatLab |
Apesar de existirem algumas limitações, os valores previstos mostraram-se satisfatórios, evidenciando que as RNA podem constituir interessante alternativa para a previsão de preços agropecuários. |
Ramos e Bräscher (2009) |
Ciência e Tecnologia |
Verificar a eficácia da Descoberta de Conhecimento em Texto (DCT) na descoberta de informações para apoio a políticas públicas. |
SAS Enterprise Miner |
Permitiu a visualização de fortes relações existentes entre os mais de 2.400 documentos que, aparentemente, não teriam interação entre si, caso apenas as classificações e palavras-chave tivessem sido consideradas. |
Gottardo, Kaestner e Noronha (2012) |
Educação |
Investigar a viabilidade de obtenção de informações de desempenho dos estudantes de Ensino à Distância (EAD) em etapas iniciais de realização do curso de forma a apoiar a tomada de ações pró-ativas. |
WEKA |
Os resultados obtidos demonstram que é possível obter estas inferências com taxas de precisão próximas a 75%, mesmo em períodos iniciais do curso. |
Fortulan e Gonçalves (2005) |
Indústria |
Desenvolver um sistema que utilize os dados resultantes do processo produtivo e os transforme em informações que auxiliem o gerente na tomada de decisões quanto a competitividade da empresa. |
Microsoft SQL Server 2000 |
Um protótipo foi construído pelos autores com os dados simulados para testar a proposta. |
Manhães et. al. (2011) |
Educação |
Identificar precocemente alunos em risco de evasão nos cursos de graduação. |
WEKA |
Os resultados mostraram que é possível identificar com precisão de 80% a situação final do aluno utilizando as primeiras notas semestrais. |
Cardoso e Machado (2008) |
Educação |
Extrair conhecimento referente à produção científica das pessoas envolvidas com pesquisa na Universidade Federal de Lavras. |
Oracle |
A contribuição foi gerar um banco de dados estruturado, que faz parte de um processo maior de desenvolvimento de indicadores de ciência e tecnologia, para auxiliar na elaboração de novas políticas de gestão científica e tecnológica e aperfeiçoamento do sistema de ensino superior brasileiro. |
Vianna et. al. (2010) |
Saúde |
Identificar padrões em características maternas e fetais na predição de |
WEKA |
O principal resultado foi a necessidade de maior atenção para as mães adolescentes de bebês que nascem com peso menor que 2,5kg, pós-termo e filhas de mães com afecções maternas, confirmando resultados de outros estudos. |
Guidini e Ribeiro (2006) |
Geoproces-samento |
Mostra um experimento de integração de um algoritmo de agrupamento na Terralib, para gerar uma classificação de dados de tráfegos aéreos desconhecidos, visando à aplicação da solução na análise destes tráfegos. |
WEKA |
Comprovou-se a possibilidade e a aplicabilidade da fusão de tecnologias, gerando aplicações úteis à tomada de decisão baseada em geoprocessamento de dados. |
Nääs et al. (2008) |
Agropecuária |
Comparar a precisão das técnicas de estimativa de estro para vacas da raça Holandesa alojadas em galpão freestall. |
WEKA |
Os resultados indicaram que, usando a observação de movimentação das vacas ou o comportamento de monta, a presença de estro pode ser detectada com maior precisão. |
Altuntas e Selim (2012) |
Industrial |
Propor uma nova abordagem para o problema de layout de facilidades a partir mineração de dados por regras de associação, em dois estudos de caso. |
Promodel |
Os resultados obtidos dos layouts foram comparados a partir da medição de desempenho, sendo eles: utilização de máquina; quantidade total de produtos produzidos, tempo de ciclo, tempo de transferência e tempo de espera em fila. Para o primeiro estudo de caso, a abordagem WARM foi a melhor, entretanto, para o segundo estudo de caso, todas as abordagens obtiveram resultados similares. |
Bae e Kim (2011) |
Industrial |
Aplicar as regras de associação e técnicas de árvores de decisão para analisar um conjunto de preferências por parte do consumidor para o desenvolvimento de um novo produto. O trabalho procura responder a algumas questões sobre o que é importante na hora de se desenvolver uma nova câmera digital. Utilizaram-se algoritmos A priori e C5.0. |
Softwares SAS Enterprise Miner 5.3 e Clementine 9.0 |
Constataram-se nove atributos funcionais e foram modeladas 4 câmeras digitais. Constatou-se a complexidade e sensibilidade da identificação dos requisitos dos clientes, entretanto a mineração de dados pode auxiliar de forma significativa nas decisões estratégicas empresariais a partir da mineração dos dados obtidos a partir das necessidades e preferências dos consumidores diretamente. |
Barack e Modarres (2015) |
Industrial |
Prever retorno e risco sobre estoques que refletem significativamente na sua precificação. Foi apresentado um modelo original de algoritmo híbrido de seleção de características baseado em filtro (filter) e o método de clusterização baseado em função (function-based clustering) foi aplicado para selecionar as características importantes. |
Rapid Miner e WEKA |
Os resultados geraram 1963 gravações para 400 companhias. O mesmo mostrou que, a sua melhor previsão para a previsão de retorno de estoques e previsão de risco Os trabalhos com os quais a recente pesquisa foi comparada tiveram uma porcentagem de sua melhor previsão, utilizando diferentes técnicas e case de classificadores e dados de entrada. |
Carvalho et al. (2012) |
Saúde |
Exemplificar e discutir a exploração de dados oriundos de acompanhamentos de pacientes de fisioterapita utilizando Mineração de Dados e o pós-processamento dos padrões (regras) descobertos. Foram realizadas as três tarefas da mineração de dados: classificação, descoberta de regras de associação e agrupamento.. |
Apriori e WEKA |
Concluiu-se que é possível a aplicação da mineração de dados na área da fisioterapia, sendo possível trabalhar com a previsão de diagnósticos fisioterapêuticos a partir de alguns dados de entrada dos pacientes, já se pensando no melhor tratamento para o indivíduo em questão, auxiliando os profissionais da área nas questões cotidianas do seu trabalho. |
Cheng, Yao e Wu (2013) |
Industrial |
Aplicar a mineração de dados para análise das causas principais de acidentes ocupacionais na indústria petroquímica. Utilizou-se a árvore de classificação e regressão e método de processamento analítico online – OLAP. |
STATISTICA Data Miner |
Para o atributo de tempo, a maioria dos acidentes ocorrem nos meses de maio, julho e novembro. Para as causas atribuídas aos fatores de tipo de trabalhadores, a maioria é homem (89%) com uma distribuição de idade entre 24 e 35 anos (36%). Para causas perigosas, a maior quantidade de pessoas que sofreram acidentes foi por meio de incêndio. Para atos inseguros, o maior número de vítimas esteve em "não uso de equipamentos de proteção". |
Lemos, Steiner e Nievola (2005) |
Financeira |
Analisar a aplicação da Mineração de Dados para avaliar clientes visando a concessão de crédito em uma agência bancária. Foram utilizadas duas técnicas de Mineração de Dados, para comparação do desempenho de cada uma delas, Árvores de Decisão e Redes Neurais |
WEKA e MatLab |
Os resultados foram obtidos a partir de oito testes para cada método, sendo que as Redes Neurais trouxeram um erro médio de classificação das empresas (adimplentes e inadimplentes) de 4,09% e 9,96% para os conjuntos de treinamento e testes, respectivamente, enquanto que as Árvores de Decisão apresentaram um erro médio de 11,49% e 28,13%, respectivamente. |
Mendes, Fiuza e Steiner |
Saúde |
Gerar padrões de reconhecimento no auxílio aos diagnósticos dos tipos mais frequentes de dores de cabeça. Os diagnósticos no momento do estudo eram feitos pela experiência de um médico que seguia os critérios da International Classification of Headaches Disorder. Utilizaram-se as RNA's no estudo. |
MatLab |
Este trabalho apresentou uma ferramenta que possibilita auxiliar as pessoas em um primeiro atendimento sobre diagnósticos de dores de cabeça, principalmente aos pacientes que não tem condições, tanto financeiras quanto em termos de disponibilidade, de ir a uma consulta com neurologista. |
Quadro 1 – Artigos relativos à aplicação de técnicas de Data Mining
Observando o Quadro 1, nota-se a diversidade de aplicações do DM e também as diferentes técnicas e softwares utilizados. Entretanto, na atual pesquisa, existe uma maior aplicação nas áreas de saúde, educação e industrial, enquanto que nas técnicas, predomina a árvore de decisão e o software WEKA (Waikato Environment for Knowledge Analisys), muito utilizado quando se aplica as árvores de decisão. As árvores de decisão são técnicas simples e muito aplicadas na mineração de dados principalmente pela sua fácil intepretação, pois utilizam variáveis categóricas que são de melhor visualização para qualquer decisor.
O presente trabalho buscou apresentar teoricamente algumas técnicas do processo KDD, que envolve a análise dos dados e DM, juntamente com algumas aplicações da literatura.
Observou-se que o processo KDD vem sendo bastante estudado e aplicado em diversas áreas do conhecimento, como saúde, educação, indústrias, financeiras, dentre outras. Existem várias técnicas disponíveis, seja para a análise dos dados, assim como para DM, sendo os autores têm procurado por uma metodologia que envolva diferentes técnicas visando obter a de melhor desempenho, seja para a tarefa de classificação, previsão, clusterização ou de associação de dados.
ALTUNTAS, S.; SELIM, H. (2012); Facility layout using weighted association rule-based data mining algorithms: Evaluation with simulation. Expert Systems with Applications, v. 39, p. 3-13.
BAE, J. K.; KIM, J. (2011); Product development with data mining techniques: A case on design of digital camera. Expert Systems and Applications, v. 38, p. 9274-9280.
BARAK, S.; MODARRES, M. (2015); Developing an approach to evaluate stocks by forecasting effective features with data mining methods. Expert Systems and Applications, v. 42, p. 1325-1339.
BENNETT, K. P.; MANGASARIAN, O. L. (1992); Robust Linear Programming Discrimination of Two Linearly Inseparable Sets. Optimization Methods and Software, London, United Kingdom, Taylor and Francis Group, v. 1, p. 23-34.
CARDOSO, O. N. P.; MACHADO, R. T. M. (2008); Gestão do conhecimento usando Data Mining: estudo de caso na Universidade Federal de Lavras. Revista de Administração Pública, v.42, n.3, p.495-528.
CARVALHO, D. R.; MOSER, A. D.; SILVA, V. A. Da; DALLAGASSA, M. R. (2012); Mineração de dados aplicados à fisioterapia. Fisioterapia em Movimento. V. 25, n. 3, p. 595-605.
CHENG, C. W.; YAO, H. Q.; WU, T. C. (2013); Applying data mining techniques to analyze the causes of major occupational accidents in the petrochemical industry. Journal of Loss Prevention in the Process Industries, v. 26, p. 1269-1278.
FAYYAD, U. M.; PIATETSKY-SHAPIRO, G.; SMYTH, P.; UTHURUSAMY, R. Advances in Knowledge Discovery & Data Mining. 1 ed. American Association for Artificial Intelligence, Menlo Park, Califórnia, 1996. 611 folhas.
FORTULAN, M. R.; FILHO, E. V. G. (2005); Uma proposta de aplicação de business intelligence no chão de fábrica. Revista Gestão & Produção, v.12, n.1, p.55-66.
FREITAS, A. A. Uma Introdução a Data Mining. (2000); Informática Brasileira em Análise, Centro de Estudos e Sistemas Avançados do Recife (C.E.S.A.R.), Recife, PE, ano II, n. 32.
GOTTARDO, E.; KAESTNER.; NORONHA, R. V. (2012); Previsão de desempenho de estudantes em cursos EAD utilizando mineração de dados: uma estratégia baseada em séries temporais. Simpósio Brasileiro de Informárica na Educação, Rio de Janeiro.
GUIDINI, M. P.; RIBEIRO, C. H. C. (2006); Utilização da biblioteca TerraLib para algoritmos de agrupamento em sistemas de informações geográficas. VIII Brazilian Symposium on GeoInformatics, São Paulo, p.303-314.
HAN, J.; KAMBER, M. (2012); Data Mining: Concepts and Techniques, ed. 1, Nova York: Morgan Kaufmann.
HORTA, R. A. M.; ALVES, F. J. S. (2012); Aplicação de técnicas de Data Mining para o entendimento da política de financiamento de empresas brasileiras. CONGRESSO ANPCONT, Rio de Janeiro.
KUSIAK, A.; ZENG, Y.; ZHANG, Z. (2013); Modeling and analysis of pumps in a wastewater treatment plant: A data-mining approach. Engineering Applications of Artificial Intelligence, v. 26, p. 1643-1651.
LAZZAROTTO, L. L.; OLIVEIRA, A. P.; LAZZAROTTO, J. J. (2006); Aspectos teóricos do Data Mining e aplicação das Redes Neurais em previsões de precos agropecuários. Congresso da Sociedade Brasileira de Economia e Sociologia Rural, Ceará.
LEMOS, E. P.; STEINER, M. T. A.; NIEVOLA, J. C. (2005); Análise de crédito bancário por meio de redes neurais e árvores de decisão: uma aplicação simples de Data Mining. Revista de Administração, v. 40, n. 3, p. 225-234.
MANHÃES, L. M. B.; CRUZ, S. M. S.; COSTA, R. J. M.; ZIMBRÃO, G. (2011); Previsão de estudantes com risco de evasão utilizando técnicas de mineração de dados. Simpósio Brasileiro de Informárica na Educação, Sergipe.
MENDES, K. B.; FIUZA, R. M.; STEINER, M. T. A. (2010); Diagnosis os headache using artificial neural networks. International Journal of Computer Science and Network Security, v. 10, n. 7, p. 172-178.
NÄÄS, I. A.; QUEIROZ, M. P. G.; MOURA, D. J.; BRUNASSI, L. A. (2008); Estimativa de estro em vacas leiteiras utilizando métodos quantitativos preditivos. Revista Ciência Rural, v.38, n.8, p.2383-2387.
NGAI, E. W. T.; XIU, L.; CHAU, D. C. K. (2009); Application of data mining techniques in customer relationship management: A literature review and classification. Expert Systems with Applications, v. 36, p. 2592-2602.
OLIVEIRA, D. M. B de; STEINER, M. T. A.; COSTA, D. M. B. (2012); Técnicas da Pesquisa Operacional na avaliação de distúrbios vocais em docentes. Revista SODEBRAS, v. 7, n. 1.
PHRIDVIRAJ, M. S. B.; GURURAO, C. V. (2014); Data Mining – past, present and future – a typical survey on data streams. Procedia Technology, v. 12, p. 255-263.
RAMOS, H. S. C.; BRÄSCHER, M. (2009); Aplicação de descoberta de conhecimento em textos para apoio à construção de indicadores infométricos para a área de C&T. Ci. Inf., Distrito Federal.
STEINER, M. T. A.; SOMA, N. Y.; SHIMIZU, T.; NIEVOLA, J. C. (2006); Abordagem de um problema médico por meio de processo KDD com ênfase à análise exploratória de dados. Gestão & Produção, v. 13, n.2, p. 325-337.
TAN, P., STEINBACH, M., KUMAR, V. (2009); Introdução ao Data Mining: Mineração de Dados. 1 ed. Rio de Janeiro: Ciência Moderna Ltda.
TRONCHONI, A. B.; ROSA, M. A. Da; PRETTO, C. O.; LEMOS, F. A. B. (2010); Descoberta de conhecimento em base de dados de eventos de desligamentos de empresas de distribuição. Revista Controle & Automação, v. 21, n. 2, p.185-200.
VIANNA, R. C. X.; MORO, C. M. C. B.; MOYSÉS, S. J.; CARVALHO, D.; NIEVOLA, J. C. (2010); Mineração de dados e características da mortalidade infantil. Cad. Saúde Pública, v.26, n.3, p.535-542.
WITTEN, I. H.; FRANK, E. (2005); Data Mining: Pratical Machine Learning Tools and Techniques. 2 ed. San Francisco, CA: Elsevier.
YAP, B. W.; ONG, S. H.; HUSAIN, N. H. M. (2011); Using data mining to improve assessment of credit worthiness via credit scoring models. Expert Systems with Applications, v. 28, p. 13274-13283.
1. Professor do curso de Bacharelado em Engenharia de Produção na Universidade Tecnológica Federal do Paraná, Câmpus Londrina, Paraná – Brasil. (brunosantos@utfpr.edu.br)
2. Professora da Pós-Graduação em Engenharia de Produção e Sistemas na Pontifícia Universidade Católica, Câmpus Curitiba, Paraná – Brasil. Bolsista de Produtividade em Pesquisa 1C - CA PE | Orientador de Doutorado (maria.steiner@pucpr.br)
3. Bacharel em Engenharia de Produção pela Pontifícia Universidade Católica, Câmpus Curitiba, Paraná – Brasil. (ramos.luishenrique@gmail.com)
4. Funcionário do Banco do Brasil S/A. (lgrmlgm@hotmail.com)
5. Professor do curso de Bacharelado em Engenharia de Produção na Universidade Tecnológica Federal do Paraná, Câmpus Londrina, Paraná – Brasil. (pedroandrade@utfpr.edu.br)