1. Introducción
El correo electrónico es utilizado como una herramienta, el cual permite enviar y recibir datos e información, archivos, gráficos o documentos. En la actualidad es utilizado como un instrumento de colaboración en las empresas para almacenar la información en un único lugar al cual los usuarios puedan acceder para transferencia de data e información tanto a entes internos como externos; estandarizar y automatizar los procesos para conseguir que el flujo de trabajo sea más eficiente, confiable y de fácil acceso.
La principal herramienta a utilizar en esta investigación es el Análisis de Modo y Efectos de Fallas (AMEF), la cual permite identificar los modos de falla potenciales en los sistemas, productos y equipos, causadas por deficiencias en las operaciones y los procesos antes de que dichas fallas ocurran. También identifica características de diseño o de proceso que requieren controles especiales para prevenir o detectar los modos de falla; por lo tanto puede ser considerado como un método analítico estandarizado para detectar y eliminar problemas. Esta metodología es utilizada por la gran cantidad de datos que de manera sistemática, ordenada y estructurada, proporciona para convertirlos en información que pueda usarse para la toma de decisiones. Para este análisis se tomó como base la metodología Yánez, M, y Semeco, K. Confiabilidad Integral: Un Enfoque Práctico (2007), Duran, J. Mantenimiento Centrado en la Confiabilidad Plus (2006), la cual permitió aplicar una serie de herramientas de confiabilidad tomando el comportamiento del activo, a fin de poder determinar el nivel de operatividad, la cuantía del riesgo y las acciones que se requieren, para asegurar su integridad y continuidad operacional. Lo novedoso en esta investigación, es su aplicación en un servicio (servicio de correo electrónico), ya que por lo general son aplicadas a equipos y componentes industriales. Los resultados obtenidos son propuestas de mejoras, permitiendo así atenuar las deficiencias del sistema, a la par de aumentar la confiabilidad mejorando la calidad del servicio.
2. Metodologías
Las metodologías de análisis de confiabilidad por lo general se utilizan en sistemas de mantenimiento específicamente en plantas de producción, en esta investigación se adaptaron a un servicio de comunicación. La aplicación del Análisis de Modo y Efectos de Fallas (AMEF) basada en los resultados del Análisis Causa Raíz (ACR) se inicia realizando una observación directa al sistema objeto de estudio (situación actual), en dicho sistema se identifican los eventos problemas calculando su respectiva frecuencia, ponderación y riesgo para así conocer los eventos críticos, continuo a ello se aplica la Matriz de Criticidad por Puntos obteniendo el evento de mayor criticidad (evento crítico). Una vez identificado el evento crítico se aplica el Análisis Causa Raíz para reconocer las causas raíces que afectan al servicio a partir de cada una de las fallas reportadas; una vez analizadas cada una de ellas mediante las tres perspectivas que contempla dicho análisis, se establecen las posible soluciones mediante el Análisis de Modo y Efectos de Fallas (AMEF) para reducir o eliminar las fallas de dicho servicio. En la siguiente figura (figura 1) se muestra de manera resumida la metodología aplicada:
Figura 1. Esquema Metodológico
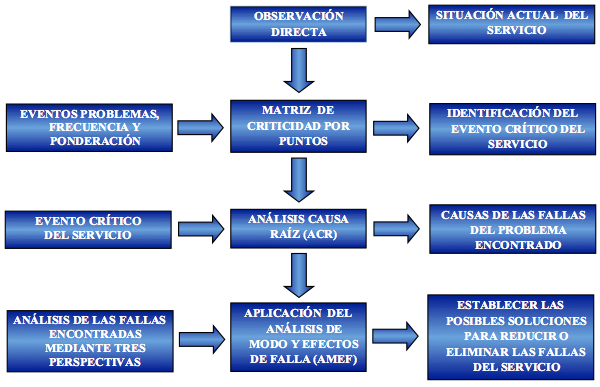
3. Aplicación de las Metodologías de Análisis de Confiabilidad: Caso de Estudio.
Actualmente la mayoría de las empresas cuentan con sistemas automatizados, PDVSA por ser una empresa que cubre toda nuestra geografía cuenta con varias gerencias de apoyo, siendo una de ellas la Gerencia de Automatización, Informática y Telecomunicaciones (AIT-SCORI), la cual se encarga de administrar, dar soporte tecnológico y soluciones integrales en el área de informática y telecomunicaciones.
Este servicio específicamente en la región oriente actualmente presenta irregularidades en su funcionamiento, lo cual genera incertidumbre y desconfianza de parte de los usuarios, impactando la imagen de AIT Servicios Comunes ante el resto de las organizaciones de PDVSA y afectando la continuidad de ciertas operaciones.
Con el fin de conocer las causas y generar posibles soluciones a esta problemática se aplicaron las metodologías de análisis de confiabilidad para así disminuir o eliminar el impacto de estas fallas, mitigar las deficiencias del sistema, a la par de aumentar la confiabilidad y eficiencia del mismo, mejorando así la calidad del servicio prestado por parte de la gerencia.
La novedad de esta investigación radica en que por primera vez se enlazan estas metodologías; la Matriz de Criticidad por Puntos, el Análisis Causa Raíz (ACR) y el Análisis de Modo y Efectos de Falla (AMEF) para el estudio de un servicio, ya que por lo general son aplicadas a equipos y componentes industriales.
3.1. Análisis de Criticidad por Puntos.
La empresa trabaja con una herramienta llamada Sistema Integral de Control y Seguimiento de Casos (SICSES); el cual es una aplicación Cliente/Servidor. Con el fin de identificar los eventos que están impactando negativamente en el funcionamiento de este servicio se utilizó el análisis de criticidad por puntos para obtener los casos o eventos asociados al correo electrónico con mayor incidencia, los cuales se clasifican, según SICSES, en tres categorías: consultas, problemas y requerimientos.
En la tabla 1, se muestran los datos arrojados por este sistema en el periodo de estudio de Enero a Diciembre de 2008, los eventos problemas del servicio de correo electrónico, así como la frecuencia de ocurrencia de estos.
Tabla 1. Eventos identificados.
EVENTOS |
Problemas |
FE (%) |
Ponderación |
Desbloqueo de Base de Datos (DBD) |
34540 |
72,33% |
50 |
Problemas con Lotus / Configuración (PLC) |
9020 |
18,89% |
50 |
Otros |
2302 |
4,82% |
20 |
Modificación (MOD) |
265 |
0,55% |
10 |
Cambio de Password por WEB (CPW) |
17 |
0,04% |
10 |
Asesoría (ASE) |
259 |
0,54% |
10 |
Creación B.D Local (CBDL) |
3 |
0,01% |
10 |
Cambio de Password (CP) |
61 |
0,13% |
10 |
Ausente de Oficina (AO) |
41 |
0,09% |
10 |
Retardo en los tiempo de respuesta (lentitud) locales y remotas (RTR) |
1008 |
2,11% |
20 |
Acceso al Correo (AC) |
239 |
0,50% |
10 |
Total |
47755 |
100,00% |
Fuente: Sistema Integral de Control y Seguimiento de casos (SICSES).
Cabe destacar que el evento retardo en los tiempos de respuestas (RTR) fue señalado por los analistas y expertos del servicio de correo, el resto fueron identificados mediante las estadísticas manejadas por la herramienta SICSES. Del mismo modo, la frecuencia se calculo por medio de una regla de tres simple, utilizando el total de los casos problemas y la cantidad casos asociados a cada evento. Dependiendo del valor obtenido en el cálculo de la frecuencia a esta se le asignó una ponderación de acuerdo a lo mostrado en la siguiente tabla 2.
Posterior a esto, se establecen los criterios de evaluación definidos por la empresa, para identificar el impacto por consecuencia de los eventos en estudio, los cuales son:
- Nivel de Solución del Evento (NSE): Es decir, el nivel correspondiente a la solución del problema o suceso ocurrido.
- Nivel de Conocimiento del Usuario (NCU): Esto si el usuario es capaz de resolver el incidente con o sin asesoría o no puede solventar la situación; Impacto Operacional (IO), es decir la repercusión sobre otros sistemas si falla el servicio.
- Flexibilidad Operacional (FO): Que se trata de la existencia o no de otras herramientas adicionales que cumplan las funciones del correo electrónico.
- Imagen (I): Esto es, la imagen ante los usuarios por los niveles de calidad y la prontitud en encontrar solución a las fallas o deficiencias encontradas.
- Frecuencia del Evento (FE): Tiene que ver con la ocurrencia anual del evento o problema.
Tabla 2. Criterios de Evaluación de Eventos.
Criterios |
Casos |
Ponderación |
Nivel de Solución del Evento (NSE) |
Nivel III (Mantenimiento de la Plataforma) |
10 |
Nivel II (Soporte Integral) |
5 |
|
Nivel I (Atención telefónica) |
1 |
|
Nivel de Conocimiento del Usuario (NSU) |
No está al alcance del usuario la solución del evento |
10 |
Está al alcance del usuario pero requiere asesoría a primer nivel |
5 |
|
Está al alcance del usuario la solución del evento |
1 |
|
Impacto Operacional (IO) |
Falla del servicio repercute en otros servicios o sistemas |
10 |
Mediano efecto sobre otros servicios o sistemas |
5 |
|
No generar ningún efecto significativo sobre otros servicios o sistemas |
1 |
|
Flexibilidad Operacional. (FO) |
No existe otra herramienta de mensajería de escritorio |
10 |
Existe una herramienta de mensajería de escritorio disponible adicional al correo PDVSA |
5 |
|
Existe más de una herramienta de mensajería de escritorio disponible adicional al correo PDVSA |
1 |
|
Imagen (I) |
Bajo niveles de respuesta para abordar la falla. |
10 |
Mediano niveles de respuesta para abordar todas las fallas. |
5 |
|
Altos niveles de respuesta para abordar la falla. |
1 |
|
Frecuencia del Evento (FE) |
El porcentaje de ocurrencia anual del evento es ≤1% |
10 |
El porcentaje de ocurrencia anual del evento es >1% y ≤ 5% |
20 |
|
El porcentaje de ocurrencia anual del evento es >5% y ≤10% |
30 |
|
El porcentaje de ocurrencia anual del evento es >10% y ≤15% |
40 |
|
El porcentaje de ocurrencia anual del evento es >15% |
50 |
Fuente: Mesa de trabajo del Servicio de Correo Electrónico.
Seguidamente de la identificación de los eventos a estudiar, sus frecuencias de ocurrencia y sus criterios de evaluación de consecuencias, se realizó el cálculo de riesgo para identificar el evento crítico. Dicho cálculo se realizó multiplicando el total de las consecuencias de cada evento por su frecuencia de ocurrencia, es decir:
Criticidad = Frecuencias*Consecuencias
En la siguiente Tabla 3, se muestra el cálculo de la criticidad de eventos.
Tabla 3. Cálculo de Criticidad de Eventos.
Evento |
Consecuencias |
Total Criticidad |
Criticidad |
|||||
Frec. |
NSE |
NSU |
IO |
FO |
I |
|||
Desbloqueo de Base de Datos (DBD) |
50 |
1 |
5 |
1 |
10 |
1 |
18 |
900 |
Problemas con Lotus / Configuración (PLC) |
50 |
5 |
5 |
1 |
5 |
1 |
17 |
850 |
Otros |
20 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Modificación (MOD) |
10 |
10 |
10 |
1 |
5 |
1 |
27 |
270 |
Cambio de Password por WEB (CPW) |
10 |
5 |
5 |
1 |
5 |
1 |
17 |
170 |
Asesoría (ASE) |
10 |
1 |
5 |
1 |
1 |
1 |
9 |
90 |
Creación B.D Local (CBDL) |
10 |
1 |
5 |
1 |
1 |
1 |
9 |
90 |
Cambio de Password (CP) |
10 |
5 |
5 |
1 |
5 |
1 |
17 |
170 |
Ausente de Oficina (AO) |
10 |
10 |
1 |
1 |
1 |
1 |
14 |
140 |
Retardo en los tiempo de respuesta (lentitud) locales y remotas (RTR) |
20 |
10 |
10 |
10 |
10 |
5 |
45 |
900 |
Acceso al Correo (AC) |
10 |
5 |
1 |
1 |
1 |
1 |
9 |
90 |
Fuente: Elaboración Propia.
Con los valores arrojados por el cálculo de la criticidad de cada evento, se procede a elaborar la matriz de criticidad, la cual facilitará la elección del evento a estudiar correspondiente al evento de mayor criticidad. En la Figura 2 se muestra la matriz de criticidad de los eventos objetos de estudio.
Figura 2. Matriz de Criticidad de los Eventos Asociados al Correo Electrónico
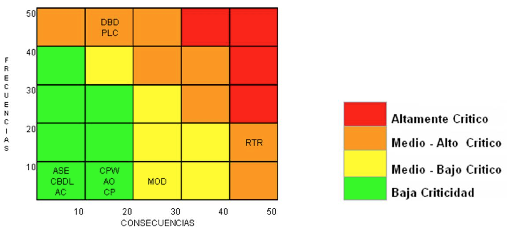
Fuente: Elaboración Propia.
Se puede observar que existen tres eventos de criticidad media alta, sin embargo, por acuerdo de la mesa de analistas, el evento DBD y PLC, han disminuido notablemente con la implantación de ciertas estrategias de divulgación del uso de correo al usuario y mejoras en los equipos. Por tanto, se acuerda que el evento Retardo en el Tiempo de Respuesta (RTR); representa el foco principal para la ejecución del Análisis Causa Raíz.
3.2. Análisis Causa Raíz.
Se elaboró el Análisis Causa Raíz de las fallas reportadas por los grupos de trabajo al foco principal “Retardo en el Tiempo de Respuesta (RTR) de la aplicación de correo electrónico”. En la figura 3, se presentan el diagrama causa raíz con cada uno los equipos de trabajo involucrados con el caso de estudio.
Figura 3. Análisis Causa Raíz del RTR de la Aplicación de Correo Electrónico
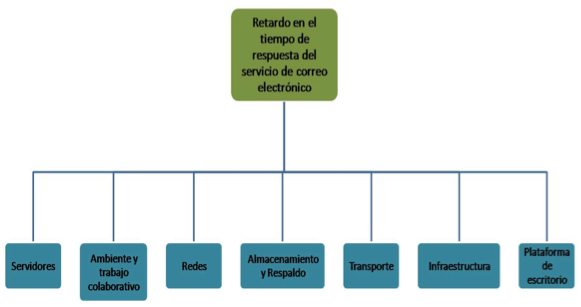
Fuente: Elaboración Propia.
De las causas identificadas se elaboró el análisis causa raíz utilizando la metodología Análisis Causa Raíz por medio del Árbol Lógico de Fallas (Yánez y Semeco, 2007; Durán 2006), el cual es un riguroso método de solución de problemas, para cualquier tipo de fallas, que utiliza la lógica sistémica y el árbol de causa raíz de fallas, usando la deducción y prueba de los hechos que conducen a las causas reales. Esta técnica permite aprender de las fallas y eliminar las causas, en lugar de corregir los síntomas.
La figura 4 muestra el árbol lógico de fallas de esta metodología, la cual se puede aplicar a cualquier tipo de falla, su objetivo es determinar el origen de una falla, la frecuencia con que aparece y el impacto que genera, por medio de un estudio profundo de los factores, condiciones, elementos y afines que podrían originarla, con la finalidad de mitigarla o eliminarla por completo de una vez tomadas las acciones correctivas que sugiere el análisis.
Figura 4 . Árbol Lógico de Fallas
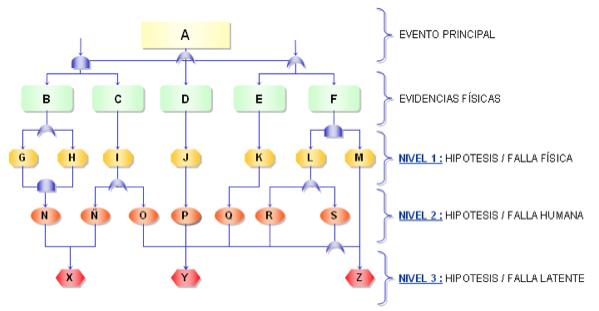
Fuente: Yánez y Semeco, 2007.
En resumen la tabla 4, se muestra cada una de las fallas encontradas y la superintendencia relacionada con el correo electrónico.
Tabla 4. Resumen de Fallas del Análisis Causa Raíz (1/2).
Superintendencias |
Fallas |
|
Servidores |
Falla en las tarjetas HBA |
Falla de tarjetas del servidor y las tarjetas HBA |
Falla en las tarjetas de los servidores |
Fallas en el software de balanceo de las tarjetas de los servidores |
|
Desperfectos electrónicos y deterioro de cableado. |
||
ATC |
Configuración en parámetros de la aplicación. |
Debilidades en los procedimientos de uso y en los acuerdos de servicio, por parte del usuario del correo electrónico |
Mantenimientos en horas de producción |
Falta de ejecución de las políticas de restricciones administrativas |
|
Sucesos imprevistos que afectan la ejecución de los mantenimientos programados en horarios nocturnos |
||
Problemas de validación de usuario |
La falta de adiestramiento al personal. |
|
Redes |
Red LAN |
Falta de políticas de seguridad a nivel de usuarios |
Falta de políticas de control y seguimiento del buen uso del servicio |
||
Falta de adiestramiento en el personal |
||
Red WAN |
Debilidades en las políticas de calidad de servicio aplicadas al correo electrónico |
|
Falta de políticas o su divulgación, acerca del uso del correo y ancho de banda permitido |
||
Fuente: Elaboración Propia.
-----
Tabla 4. Resumen de Fallas del Análisis Causa Raíz (2/2).
Superintendencias |
Fallas |
|
Almacenamiento y Respaldo |
Prolongación de la ventana de respaldo |
La inadecuada cultura de respaldo de data del correo por parte del usuario |
Aumento en el requerimiento del espacio del servicio de correo |
||
Crecimiento de usuarios concurrentes |
||
Configuración inadecuada de la plataforma de almacenamiento |
Falta de visualización de usos futuros del servicio |
|
Desconocimiento de AIT de las necesidades del servicio |
||
Debilidades en el plan de crecimiento del negocio |
||
Transporte |
Falla de conexión del servicio de fibra |
La falta de mantenimiento, fallos en red de energía publica aparición de casos fortuitos |
Sabotajes o casos fortuitos |
||
La falta de un mantenimiento efectivo aparte de las condiciones ambientales |
||
Infraestructura |
Falla en el sistema de aire acondicionado |
Problemas con el aire acondicionado que afectan la temperatura ideal de funcionamiento de los equipos del centro de computo del servicio de correo |
Plataforma de Escritorio |
Obsolescencia de tecnologías de los equipos |
Falta de plan de inversión de tecnologías y de equipos |
Falta de estrategias de actualización de tecnologías |
||
Deficiencia de los procesos y de políticas gerenciales |
||
Fuente: Elaboración Propia.
3.3. Análisis de Modos y Efectos de Fallas.
Una vez realizado el Análisis Causa Raíz, e identificado cada una de las causas de fallas del sistema, se procedió a elaborar un Análisis de Modo y Efectos de Falla para el servicio de correo electrónico, a fin de documentar el proceso e identificar las acciones que podrán eliminar o reducir la ocurrencia de las fallas potenciales del correo electrónico. Para realizar el cálculo del riesgo, se utilizó la formula:
Riesgo = Severidad x Ocurrencia
La ocurrencia de eventos se determinó mediante el promedio de fallas por mes de cada uno de los equipos involucrados con el correo electrónico, desde enero a diciembre del año 2008.
La severidad tiene que ver con el impacto que dicha falla traería al servicio de correo electrónico, estos valores se estimaron mediante reuniones realizadas con los encargados del sistema.
Desde la tabla 5 hasta la tabla 11 se muestran los posibles modos de falla de cada disciplina relacionada con el correo electrónico, así como el cálculo del nivel de riesgo de cada falla, y las acciones recomendadas para mitigar estas, los encargados ejecutarlas y la frecuencia con que se deben efectuar.
En la tabla 12 se muestra un resumen de la o las fallas más críticas por cada departamento, que son las que presentan el valor de riesgo más elevado, y las acciones pertinentes a realizar para mitigar estas fallas.
Tabla 5. AMEF para el Departamento de Servidores
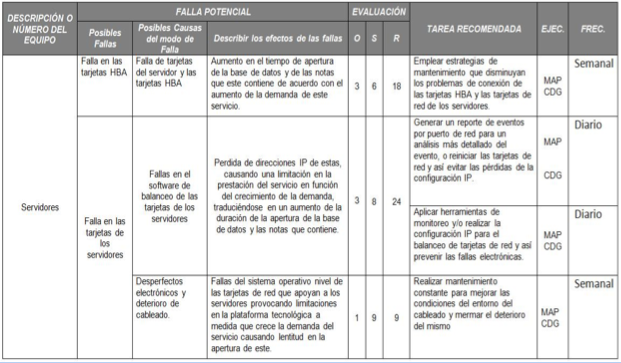
Fuente. Elaboración Propia.
-----
Tabla 6. AMEF para el Departamento de ATC
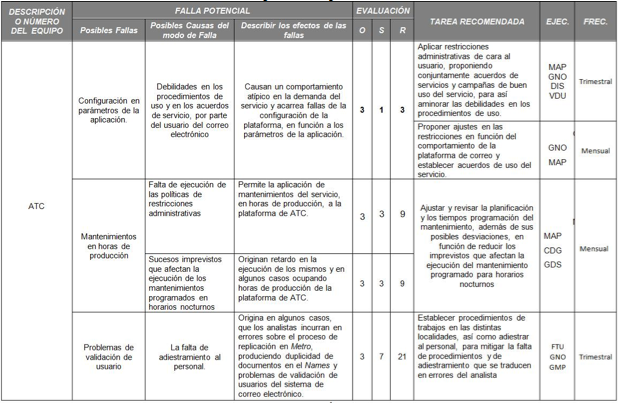
Fuente. Elaboración Propia.
-----
Tabla 7. AMEF para el Departamento de Redes
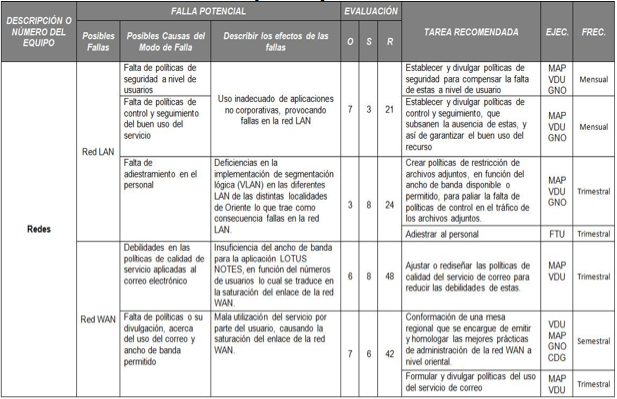
Fuente. Elaboración Propia.
-----
Tabla 8. AMEF para el Departamento de Almacenamiento y Respaldo
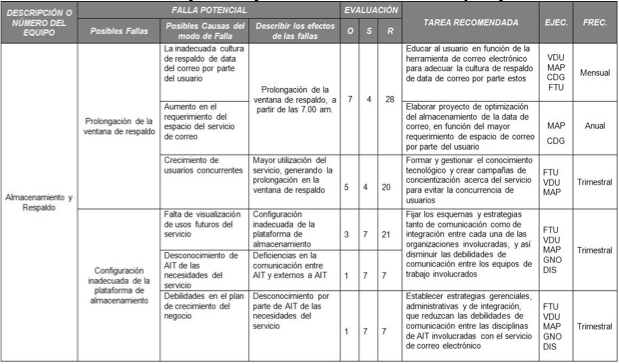
Fuente. Elaboración Propia.
-----
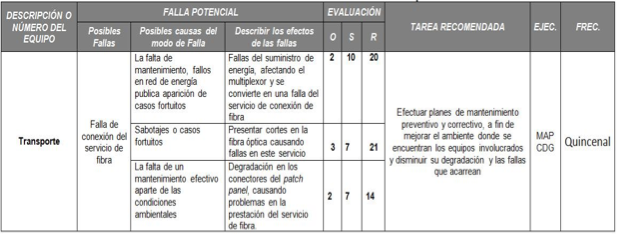
Tabla 9. AMEF para el Departamento de Transporte
Fuente. Elaboración Propia.
-----
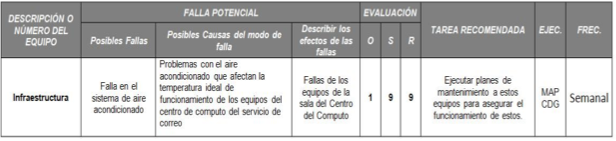
Tabla 10. AMEF para el Departamento de Infraestructura
Fuente. Elaboración Propia.
-----
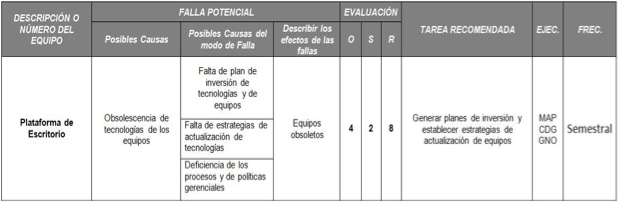
Tabla 11. AMEF para el Departamento de Plataforma de Escritorio
Fuente. Elaboración Propia.
-----
Tabla 12. Resumen de Fallas por Superintendencias.
Superintendencias |
Falla |
Nivel de Riesgo |
Acciones Pertinentes |
Servidores |
Fallas en el software de balanceo de las tarjetas de los servidores |
24 |
Generar un reporte de eventos por puerto de red para un análisis más detallado del evento, o reiniciar las tarjetas de red y así evitar las pérdidas de la configuración IP. |
Aplicar herramientas de monitoreo y/o realizar la configuración IP para el balanceo de tarjetas de red y así prevenir las fallas electrónicas |
|||
ATC |
La falta de adiestramiento al personal. |
21 |
Establecer procedimientos de trabajos en las distintas localidades, así como adiestrar al personal, para mitigar la falta de procedimientos y de adiestramiento que se traducen en errores del analista |
Redes |
Debilidades en las políticas de calidad de servicio aplicadas al correo electrónico |
48 |
Ajustar o rediseñar las políticas de calidad del servicio de correo para reducir las debilidades de estas. |
Almacenamiento y Respaldo |
Prolongación de la ventana de respaldo, a partir de las 7.00 am |
28 |
Educar al usuario en función de la herramienta de correo electrónico para adecuar la cultura de respaldo de data de correo por parte estos |
Elaborar proyecto de optimización del almacenamiento de la data de correo, en función del mayor requerimiento de espacio de correo por parte del usuario |
|||
Transporte |
Sabotajes o casos fortuitos |
21 |
Efectuar planes de mantenimiento preventivo y correctivo, a fin de mejorar el ambiente donde se encuentran los equipos involucrados y disminuir su degradación y las fallas que acarrean |
Infraestructura |
Falla en el sistema de aire acondicionado |
9 |
Ejecutar planes de mantenimiento para asegurar el buen funcionamiento de los equipos |
Plataforma de Escritorio |
Obsolescencia de tecnologías de los equipos |
8 |
Generar planes de inversión y establecer estrategias de actualización de equipos |
Fuente. Elaboración Propia.
De la anterior tabla se observa que la superintendencia más crítica es la de Redes y que la falla critica es la debilidad existente en las políticas de calidad de servicio de correo electrónico.
4. Conclusiones
La confiabilidad como metodología de análisis debe soportarse en una serie de herramientas que permitan evaluar el comportamiento del activo de una forma sistemática a fin de poder determinar el nivel de operatividad, la cuantía del riesgo y las demás acciones que se requieren para asegurar su integridad y continuidad operacional; en esta investigación el activo lo represento un servicio de allí la novedad en la aplicación de las mismas.
Aplicando la metodología de la Matriz de Criticidad por Puntos se halló el problema más crítico el cual fue el retardo en el tiempo de respuesta de la aplicación de correo electrónico, ya que el valor arrojado en el cálculo de su criticidad fue el más elevado de todos los eventos identificados.
Tomando como base el problema critico a través del Análisis Causa Raíz, se encontró que las causas que originan problemas en la prestación del servicio son de carácter humano, encontrándose entre estas la falta de buenas políticas de calidad del servicio, así como las deficiencias en la elaboración y ejecución de planes de mantenimiento de la aplicación, la falta de adiestramiento al personal encargado de velar por el servicio, y la ausencia de campañas de información orientadas al buen uso del correo electrónico.
Mediante el Análisis de Modo y Efectos de Fallas se establecieron las posibles soluciones a la problemática planteada, estas son: aplicar herramientas de monitoreo a los equipos para generar un plan de mantenimiento que garantice el funcionamiento continuo del servicio y definir políticas de calidad para aprovechar al máximo las ventajas de este servicio y a la vez garantizar la satisfacción del usuario.
5. Referencias Bibliográficas
[1] Duran, J. (2006). Mantenimiento Centrado en la Confiabilidad Plus.(2a ed.). Caracas, Venezuela: The Woodhouse Parnertship Limited.
[2] Yánez, M, y Semeco, K. (2007). Confiabilidad Integral: Un Enfoque Práctico (1a ed.). Caracas, Venezuela.
[3] SMITH, A. (1992). ReliabilityCentered Maintenance. New York, EEUU: McGraw Hill Inc.
[4] García, O. (2005). El Análisis Causa Raíz, Estrategia de Confiabilidad[Página web en línea]. Disponible en: http://noria.com/sp/rw2005/memorias/ogarcia.pdf
[5] BQR Reliability Engineering, (2009). [Página web en línea]. Disponible en: http://www.bqr.com/content/view/52/69/lang,sp/
[6] Norma Nacional Americana (PMBOK). (2004). Fundamentos de la Dirección de Proyectos. [Programa de computación]. Chicago: Project Management Institute.