1. Introdução
Metodologias de processamento de imagens estão sendo cada vez mais estudadas procurando automatizar atividades em diversas áreas, como por exemplo, a identificação de áreas de culturas agrícolas com o uso de técnicas de geoprocessamento e sensoriamento remoto para o monitoramento e a estimativa de safras agrícolas. Estas atividades, até então, são realizadas através da aplicação de questionários respondidos pelos próprios produtores ou pelas entidades relacionadas à atividade agrícola da região (Ibge, 2002).
Tais metodologias se utilizam das informações oferecidas pelos sensores de satélites na tentativa de suprir a necessidade cada vez maior de instituições públicas e privadas envolvidas com o setor agrícola em técnicas avançadas de agricultura de precisão, podendo mudar a forma que os produtores gerenciam suas terras (Pinter Jr. et al., 2003).
No contexto de análise de culturas agrícolas, pode-se citar o trabalho de Rudorff et al. (2010) que analisaram a expansão das culturas de cana-de-açúcar e as mudanças do uso da terra no estado de São Paulo fazendo uso de imagens Landsat, a partir do qual concluíram que as imagens de sensoriamento remoto conseguem fornecer informações importantes sobre as culturas de cana-de-açúcar possibilitando resultados quantitativos relevantes.
Em se tratando de métodos para classificação, as redes neurais artificiais estão sendo ultimamente bastante utilizadas para classificação de padrões e foi o método escolhido para compor a metodologia, pois de acordo com Yuan et al. (2009) e Haykin (1998), as redes neurais oferecem vantagens sobre os métodos estatísticos por usarem processamento paralelo, possuírem a habilidade de estimar relacionamentos não lineares entre dados de entrada e a saída desejada e ainda uma capacidade de generalização rápida.
No contexto das redes neurais e classificação de padrões em imagens de satélite, cita-se Yuan et al. (2009), que fizeram um estudo de caso utilizando três tipos de redes neurais aplicadas na classificação do uso e cobertura da terra, incluindo culturas agrícolas, usando imagens do sensor Thematic Mapper (TM) do satélite Landsat (Landsat TM 5, 1987-1988), cujos resultados foram satisfatórios e a rede perceptrons de múltiplas camadas obteve o melhor desempenho dentre as três redes analisadas.
E frente a esse cenário nota-se, portanto a importância em pesquisar, propor e testar métodos para à extração de áreas de culturas agrícolas, dentre elas a cana-de-açúcar, devido à sua relevância para a região Centro-Sul do Brasil (Rudorff et al., 2010) e para o próprio país como o maior produtor de cana-de-açúcar do mundo (Brasil, [200-]). O estudo mostrado neste artigo foi realizado na região da Bacia Hidrográfica do Alto Rio Paraguai (BHARP), na qual se encontra inserido o Pantanal brasileiro, representando 38,21% da área da bacia (Silva, Abdon, 1998).
2. Objetivo
Este trabalho teve como objetivo o desenvolvimento de uma metodologia para identificar e classificar regiões de culturas de cana-de-açúcar na região da Bacia Hidrográfica do Alto Rio Paraguai, Mato Grosso, Brasil, utilizando uma rede neural artificial do tipo Perceptron de múltiplas camadas treinada pelo algoritmo backpropagation, uma medida de contraste como parte dos parâmetros de entrada da rede e imagens do sensor TM do satélite Landsat 5.
3. Material e Métodos
A área de estudo está localizada entre as coordenadas 14º50'59,76” S, 57º14'41,39” W e 14º59'10,63” S, 57º04'40,05” W, na região norte do município de Barra do Bugres-MT, onde se verifica a presença de talhões de cana-de-açúcar, usados principalmente para a fabricação de biocombustível e açúcar pela empresa Barralcool, também de uma pequena área urbana, de regiões de floresta, solo exposto, pastagem e rios (Figura 1). Foram utilizadas imagens do sensor TM do satélite Landsat 5 (Landsat TM 5, 1987-1988) para esta área do dia 31 de Maio de 2011, um mês após o início do período de colheita. Estas imagens foram adquiridas junto ao INPE (Instituto Nacional de Pesquisas Espaciais) gratuitamente para fins de pesquisa. As bandas usadas foram a 3, 4 e 5, que correspondem à região espectral do vermelho, infravermelho próximo e infravermelho médio, respectivamente, e ainda o índice de vegetação Normalized Difference Vegetation Index (NDVI).
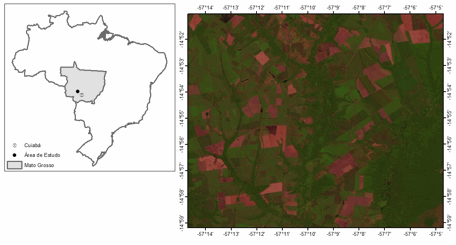
Figura 1. A?ea de estudo (Fonte: Grupo de Pesquisa em Ciências Exatas Agrárias e Ambientais, GPCEAA).
O software que gera a imagem NDVI (Figura 2), que faz o cálculo da medida de contraste, que gera, treina e aplica a rede neural foi desenvolvido na linguagem de programação C++, utilizando o framework da Nokia, Qt versão (Nokia, 2008).
Segundo Tucker (1979), o NDVI foi desenvolvido para monitorar diferentes tipos de vegetação devido à sua sensibilidade ao verde fotossintéticamente ativo e à forte biomassa de vegetações, sua fórmula é descrita na Equação 1:
![]() (1)
(1)
onde R é a banda do vermelho e IR a banda do infravermelho próximo.

Figura 2. Imagem NDVI.
3.1. Redes neurais artificiais
Para Haykin (1998) e Braga et al. (2000), uma rede neural é um sistema de processamento distribuído e paralelo formado por unidades simples de processamento, que armazenam o conhecimento empírico e o tornam apto para utilização. Este conhecimento é obtido do ambiente através de um processo de aprendizagem e as ligações entre essas unidades são usadas para armazenar este conhecimento. As unidades são chamadas de neurônios e as conexões de pesos sinápticos. Haykin (1998) explica que o processo de aprendizagem ou algoritmo de aprendizagem modifica os pesos sinápticos da rede de forma a treiná-la para alcançar determinado objetivo.
Redes com uma camada de entrada, uma ou mais camadas internas e uma camada de saída, que utilize uma função de ativação (cálculo feito por um neurônio com os valores vindos das suas ligações) não linear, com alto grau de conectividade entre os neurônios, onde o sinal de entrada é propagado pela rede de camada em camada, a partir da camada de entrada até a camada de saída, e que usam algoritmos supervisioandos para treinamento, são chamadas de redes perceptron multicamadas (Multilayer Perceptron, MLP) (Haykin, 1998). Um exemplo de uma rede MLP é mostrada na Figura 3.
Estas redes surgiram para resolver problemas não linearmente separáveis e vem sendo utilizadas em diversos problemas com sucesso (Haykin, 1998), utilizando como treinamento um algoritmo supervisionado conhecido como retropropagação do erro ou backpropagation. Neste trabalho utilizou-se desta arquitetura e deste algoritmo de treinamento.
A função de ativação usada neste trabalho é a função sigmóide, dada pela Equação 2:
![]() (2)
(2)
onde a constante α determina o grau de inclinação da função sigmóide.
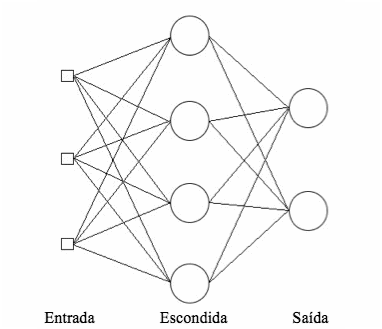
Figura 3. Exemplo da arquitetura de uma rede neural MLP com 3 neurônios na camada de entrada, 4 na camada oculta e 2 na camada de saída.
O algoritmo backpropagation considera toda a rede como uma função e altera seus termos para que o erro calculado pela diferença do valor esperado com o valor gerado por algum determinado neurônio na camada de saída seja menor a cada iteração do algoritmo. Desta forma toma-se a equação do erro em função do termo que se deseja alterar. Os termos que são alterados são os pesos das conexões sinápticas, um de cada vez. No algoritmo usado neste trabalho há duas constantes que influenciam no aprendizado da rede, a taxa de aprendizado e a constante momentum. A primeira determina a velocidade com que os pesos são ajustados de forma a diminuir o erro. A segunda ajuda a garantir que o erro convirja para um valor mínimo.
3.2. Matriz de coocorrência
Para obter a medida do contraste fez-se uso da matriz de coocorrência, método desenvolvido por Haralick et al. (1973) e explicado também por Liberman (1997), cuja finalidade é prover informações estatísticas para então calcular diferentes medidas ou feições de textura, dentre elas, o contraste. Estas informações estatísticas são o número de ocorrências de um pixel com determinado nível de cinza ser vizinho em uma dada direção e uma dada distância de um outro pixel com outro determinado nível de cinza em forma de uma matriz, cujas coordenadas são os diferentes níveis de cinza e os elementos o número de ocorrências. Em outras palavras, dada uma matriz de coocorrência C, o elemento Cij é o número de ocorrências em que um pixel com nível de cinza i é vizinho, segundo uma determinada direção e uma distância, de um pixel com o nível de cinza j. As direções podem ser 4: horizontal, vertical, diagonal principal e diagonal secundária.
A medida para o contraste é obtida através da matriz de coocorrência pela da Equação 3:
![]() (3)
(3)
onde cij é o valor do elemento da matriz de coocorrência nas coordenadas (i, j) normalizados pela soma dos elementos da matriz.
A fórmula para o contraste gera valores maiores que 1, por isso uma pequena adaptação foi feita, para que ela gere valores menores que 1, ficando na faixa de valores com que as redes trabalham. Isto foi feito normalizando i e j por 255. Além disto, uma alteração no algoritmo para gerar a matriz de coocorrência foi feita para que esta ocupasse menos espaço e consequentemente menos processamento fosse necessário. Esta alteração se baseou no fato de que em uma janela 3 x 3, por exemplo, há a possibilidade de no máximo 9 valores de níveis de cinza diferentes, um valor bem inferior à 255, que é o número de níveis de cinza possíveis em uma imagem de 8 bits. Logo seria dispendioso se a matriz guardasse espaço para todos os outros níveis que não estão na janela. Assim, nesta pesquisa, a matriz guarda somente as frequências para os níveis de cinza presentes na janela usada.
3.3. Metodologia proposta
Foram criadas, treinadas e testadas 23 redes MLP com o objetivo de identificar e classificar 4 padrões envolvendo culturas de cana-de-açúcar: cana soca madura (denominada “Cana 1”), cana soca pouco produtiva (denominada “Cana 2”), áreas em reforma (denominada “Reforma”) e áreas que utilizaram queimadas (denominada “Queimada”) para a colheita. Estas áreas foram identificadas baseando-se no trabalho de Rudorff et al. (2010). Embora somente estas 4 sejam as classes de interesse, as redes foram treinadas para reconhecerem floresta, estradas e áreas com outros usos, como pastagem e área urbana, a fim de que a rede não confundisse as classes de interesse com as demais na classificação.
As redes diferem entre si pelo tipo de entrada, pela configuração das camadas ocultas (internas), pela quantidade de classes e pelo conjunto de treinamento utilizado. Quanto ao tipo de entrada, algumas redes utilizaram as três bandas (3, 4 e 5) somente e as demais utilizaram, além das três bandas, a imagem NDVI. Todas as redes usaram a medida do contraste como entrada. Assim, para aquelas que utilizaram somente as bandas, foram necessários 39 neurônios na camada de entrada, pois foi utilizada uma janela de 3 x 3 pixels, totalizando 9 pixels para cada uma das bandas, além disso, foram calculadas 4 matrizes de coocorrência para cada janela, uma para cada direção. Para as redes que usaram o NDVI, foram necessários 52 neurônios na camada de entrada, pois mais 9 valores para os pixels da janela da imagem NDVI e as 4 medidas de contraste, uma para cada matriz de coocorrência foram acrescentados. É importante relatar que os valores dos pixels foram normalizados por 255 antes de serem passados para as redes.
Quanto à quantidade de classes, algumas redes foram treinadas para reconhecerem 5 classes: cana soca madura, cana soca pouco produtiva, áreas em reforma, áreas queimadas e estradas e floresta, estas duas como uma única classe. Outras redes foram treinadas com 7 classes, onde a estrada e floresta foram colocadas como classes separadas e uma sétima classe foi adicionada para outros usos da terra. A configuração das camadas ocultas foi determinada de forma empírica através do andamento dos próprios testes e baseado em experiências passadas. Além disso, foram utilizados 12 conjuntos diferentes de treinamento, isto na tentativa de encontrar o melhor conjunto de treinamento, ou seja, aquele que conseguisse abranger da melhor forma possível as situações com as quais a rede terá que lidar.
Uma classificação manual foi realizada para as 4 classes de interesse para analisar quantitativamente o método escolhido através da elaboração da matriz de confusão (matriz de erro) e utilizando um método descritivo e outro analítico para determinação da acurácia, o cálculo da acurácia global e o índice Kappa, respectivamente, ambos baseados na matriz de erro. Todo o processo de análise dos resultados foi baseado no trabalho de Congalton (1991).
4. Resultados e Discussão
Durante os testes realizados com as 23 redes neurais, percebeu-se a importância e a influência do conjunto de treinamento utilizado no resultado da classificação, dessa forma foram alterados alguns conjuntos na tentativa de representar melhor as situações com que as redes deveriam trabalhar. Também constatou-se que as redes que utilizaram a imagem NDVI como entrada geraram um melhor resultado na classificação, o que pode ser explicado pelo simples fato dos valores da imagem NDVI representarem uma informação adicional sobre as classes de vegetação, favorecendo principalmente a diferenciação das plantações de cana-de-açúcar e a floresta.
Os resultados apresentados aqui são referentes a rede que obteve a melhor classificação. Esta rede utilizou as três bandas e a imagem NDVI como entrada, bem como a medida de contraste. A estrutura desta rede foi de 52 neurônios na camada de entrada para receber os valores dos níveis de cinza de janelas de 3 x 3 pixels para cada uma das 3 bandas e a imagem NDVI, totalizando 36 valores, mais 4 medidas de contraste (uma para cada direção) para cada uma das 3 bandas e a imagem NDVI, totalizando 16 valores; 9 neurônios na camada escondida, determinados empiricamente; 7 neurônios na camada de saída, um para cada classe determinada. A constante α da função de ativação dos neurônios foi igual a 2, determinados de forma empírica.
No treinamento desta rede com o algoritmo backpropagation foram utilizados a constante de momentum igual a 0,2 e a taxa de aprendizado igual a 0,5. O erro máximo permitido como critério de parada do treinamento foi igual a 0,00005. O conjunto de treinamento final foi construído na tentativa de melhor representar cada uma das classes. Foram escolhidas amostras que exemplificassem tantos casos que as redes teriam de lidar quanto possíveis, de forma iterativa, a cada teste realizado. Estas amostras foram escolhidas uma a uma como descrito acima, totalizando 66.
A Figura 4 mostra o resultado da classificação para as 4 classes de interesse e o Quadro 1 mostra a matriz de confusão elaborada comparando a classificação obtida com as redes neurais e a classificação manual para as classes de interesse. O Quadro 2 mostra o resultado dos cálculos da acurácia obtido, o que inclui a acurácia de usuário para cada classe, a acurácia de produtor para cada classe, a acurácia global e a estimativa do índice Kappa (Congalton, 1991).
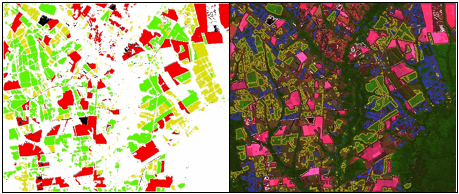
(a) (b)
Figura 4.
Imagens resultado da classificação.
(a) regiões classificadas:
Cana 1 (verde), Cana 2 (amarelo), Reforma (vermelho),
Queimada (preto) e outros usos (branco);
(b) bordas das regiões classificadas
sobrepostas à composição colorida (5R4G3B):
Cana 1 (amarelo), Cana 2 (azul), Reforma (preto)
e Queimada (branco).
--------
Quadro 1. Matriz de confusão para o resultado da classificação.
|
|
Classificação da rede |
|
||||
|
|
Cana 1 |
Cana 2 |
Reforma |
Queimada |
Total das linhas |
TOTAL |
Classificação manual |
Cana 1 |
34201 |
260 |
103 |
2 |
34566 |
44331 |
Cana 2 |
1106 |
16666 |
36 |
127 |
17935 |
27888 |
|
Reforma |
5 |
0 |
35589 |
400 |
35994 |
40831 |
|
Queimada |
0 |
0 |
26 |
850 |
876 |
1008 |
|
Total das colunas |
35312 |
16926 |
35754 |
1379 |
89371 |
114058 |
|
Outros |
5693 |
4787 |
4374 |
1894 |
16748 |
|
|
|
TOTAL |
41005 |
21713 |
40128 |
3273 |
106119 |
|
-------
Quadro 2. Acurácia da classificação.
|
Acurácia do usuário |
Acurácia do produtor |
Acurácia global do usuário |
Acurácia global do produtor |
Kappa/Khat |
Cana 1 |
83,4% |
77,15% |
82,27% |
76,54% |
68,86% |
Cana 2 |
76,75% |
59,76% |
|||
Reforma |
88,68% |
87,16% |
|||
Queimada |
25,97% |
84,32% |
A matriz de confusão poderia ser calculada com amostras devido à disparidade entre o número de pixels pertencentes às diferentes classes na área de estudo, porém isto poderia afetar negativamente a análise, favorecendo ou não o método. Portanto, optou-se por utilizar todo o conteúdo da área de estudo.
A linha “Outros” do Quadro 1 é referente aos pixels que foram classificados pela rede como pertencentes a alguma das classes de interesses, mas que segundo a classificação manual pertencem a outros usos, como florestas, estradas, área urbana e etc. Pelo fato das 4 classes definidas não abrangerem todas as imagens usadas na classificação, o número total de pixels classificados pela rede não é o mesmo para a classificação manual, sendo assim, não se tem um único número total de amostras, mas dois números. Os números totais de amostras classificadas são mostrados na linha e coluna “TOTAL” do Quadro 1.
De acordo com Congalton (1991), a acurácia do usuário revela a porcentagem de pixels que foram classificados corretamente dentre todos aqueles que foram classificados, em outras palavras, quanto menor este valor, maior a quantidade de falsos positivos. Já a acurácia do produtor mostra a probabilidade de um pixel que de fato pertence a uma classe, ser classificado corretamente, ou seja, a porcentagem de pixels que deveriam ser classificados como uma classe e que realmente foram, desta forma quanto menor este valor, maior o número de falsos negativos. Segundo o mesmo autor, a acurácia global é calculada pela razão entre a soma dos elementos da diagonal principal da matriz de erro pelo número total de amostras, como já explicado, tem-se dois números total de amostras, por isso, foram calculados dois valores para a acurácia global, um em relação ao número total de amostras classificadas manualmente (produtor) e o outro pela classificação da rede (usuário).
A fórmula para o valor Khat, que representa o índice Kappa pode ser encontrada em Coelho (2010), Congalton (1991) e Silva et al. (2011). Nesta pesquisa optou-se por calcular o valor Khat apenas uma vez utilizando uma média entre os números totais de amostras ao invés de calcular para ambos os números.
Nota-se a diferença entre os valores das acurácias globais e o valor Khat, isto se dá, pois, segundo Congalton (1991), estes valores representam informações diferentes da matriz de confusão e recomenda que sejam usados em conjunto, por este motivo.
Com base nas imagens, na matriz de confusão e nas acurácias calculadas pode-se afirmar que a rede foi capaz de classificar a maioria das regiões corretamente, porém o número de falsos positivos foi relativamente grande, principalmente para a classe “Queimada” (74,03%), ou seja, embora quase toda a região que usou queimada para a colheita tenha sido identificada, como mostra o valor da acurácia do produtor para esta classe, muitas áreas que não fazem parte deste padrão foram classificadas como pertencentes a esta classe, principalmente áreas de estradas e regiões com água, esta última pela sua tonalidade escura (baixos valores dos níveis de cinza), por esta razão a classe “Queimada” foi a que obteve a menor acurácia e influenciou negativamente na acurácia global da classificação obtida pela rede, que foi de 82,27% de acurácia global do usuário, 76,54% de acurácia global do produtor e 68,86% para o índice Kappa.
A classe “Cana 1” obteve valores de acurácia bons tanto para a do usuário (83,4%) como para a do produtor (77,15%). As áreas que foram classificadas de forma errada, ou seja, que representam os falsos positivos, são regiões de cana soca pouco produtiva (Cana 2) e regiões de floresta. A rede conseguiu classificar bem a classe “Cana 2”, mas teve uma porcentagem de falsos negativos considerável (40,24%), em outras palavras, ela deixou de classificar uma área considerável. A maior influência no resultado da classificação deste padrão é atribuída ao conjunto de treinamento. Os falsos positivos para esta classe foram ocasionados por alguns pixels da classe “Cana 1”, regiões de floresta e pastagens. Já a classe “Reforma”, que obteve a maior acurácia (88,68% de acurácia do usuário e 87,16% de acurácia do produtor) devido à sua faixa de valores dos níveis de cinza, bastante diferente das classes de vegetação, porém semelhante às regiões de estradas e área urbana, o que resultou nos 11,32% de falsos positivos.
5. Conclusões e Sugestões
O método proposto se mostrou viável, muito embora o número de falsos positivos para a classe “Queimada” tenha sido de quase 75% em relação ao número de pixels classificados, ações para corrigir este problema podem ser tomadas, como a elaboração de um conjunto de treinamento mais apropriado, visto que este foi um dos fatores que influenciou diretamente no resultado das classificações das redes testadas, e o uso de outras características das classes além dos valores dos níveis de cinza e a medida de contraste.
Destaca-se também a influência da imagem NDVI nos resultados, sendo que as redes que utilizaram os valores dos níveis de cinza da imagem NDVI obtiveram melhores classificações. Além disto, uma vez que se obteve uma rede treinada para reconhecer estes padrões, ela agora pode ser aplicada em outras imagens obtendo a classificação destes padrões automaticamente, sem a necessidade de se repetir os procedimentos supervisionados, porém as imagens devem possuir as mesmas características radiométricas e espectrais, o que provavelmente demandará correções radiométricas e atmosféricas, para garantir a precisão nos resultados da aplicação da metodologia.
6. Agradecimentos
Os autores agradecem à FAPEMAT pelo apoio em forma de bolsa de iniciação científica e ao INPE pelo fornecimento das imagens Landsat 5 utilizadas no trabalho.
7. Referências
Braga, A. P.; Carvalho, A. P. L. F.; Ludermir, T. B. (2000); "Redes neurais artificiais: teoria e aplicações". Rio de Janeiro: LTC.
Brasil, Ministério da Agricultura. Cana-de-açúcar. Site do Ministério da Agricultura do Brasil, [200-]. Disponível em: <http://www.agricultura.gov.br/vegetal/culturas/cana-de-acucar>. Acesso em: 21 set. 2011.
Coelho, F. F. (2010); Comparação de métodos de mapeamento digital de solos através de variáveis geomorfométricas e sistemas de informações geográficas. Dissertação (Mestrado em Sensoriamento Remoto) – Universidade Federal do Rio Grande do Sul, UFRGS. Porto Alegre: UFRGS.
Congalton, R. G. (1991); "A review of assessing the accuracy of classifications of remotely sensed data". Remote Sensing of Environment. n. 37, 1991, 35-46.
GPCEAA, Grupo de Pesquisa em Ciências Exatas, Agrárias e Ambientais. Universidade do Estado de Mato Grosso – UNEMAT. 8 pesquisadores, 40 estudantes. Endereço eletrônico: <http://dgp.cnpq.br/buscaoperacional/detalhegrupo.jsp?grupo=8415101CMT3EOV>.
Haralick, R. M.; Shanmugam, K. (1973); Its'Hak Dinstein. Textural features for image classification. IEEE Transactions on Systems, Man and Cybernetics. v. SMC-3, n. 6. New York: IEEE, p. 610-621.
Haykin, S.(1998); "Neural networks: a comprehensive foundation". 2. ed. Upper Saddle River, New Jersey: Prentice Hall.
IBGE (2002); "Departamento de Agropecuária. Pesquisas agropecuárias". 2. ed., Rio de Janeiro: IBGE, 92. Série Relatórios Metodológicos, v. 6.
Landsat TM 5: imagem de satélite. São José dos Campos: Instituto Nacional de Pesquisas Espaciais, INPE, 1987-1988. 1 fotografia aérea. Escala 1:100.000. Bandas 3, 4 e 5.
Liberman, F. (1997); Classificação de imagens digitais por textura usando redes neurais. 87 f. Dissertação (Mestrado em Ciência da Computação) – Universidade Federal do Rio Grande do Sul, Porto Alegre.
Nokia Corporation. Qt SDK. Versão 1.2.1. [S.l.]: Nokia Corporation, 2008. Disponível em: <http://qt.nokia.com/downloads>. Acesso em: 12 mar. 2011.
Pinter Jr, P. J.; Hatfield, J. L.; Schepers, J. S.; Barnes, E. M.; Moran, M. S.; Daughtry, C. S. T.; Upchurch, D. R. (2003); Remote sensing for crop management. Photogrammetric Engineering & Remote Sensing, v. 69, n. 6, p. 647-664.
Rudorff, B. F. T.; Aguiar, D. A.; Silva, W. F.; Sugawara, L. M.; Adami, M.; Moreira, M. A. (2010); Studies on the rapid expansion of sugarcane for ethanol production in São Paulo state (Brazil) using Landsat data. Journal of Remote Sensing. n. 2, p. 1057-1076.
Silva, A. M.; Mello, J. R. B.; Boshi, R. S.; Rocha, J. V.; Lamparelli, R. A. C. (2011); Avaliação de classificadores para o mapeamento de uso da terra. In: Simpósio Brasileiro de Sensoriamento Remoto, 15., Curitiba-PR, 2011. Anais... São José dos Campos: INPE, p. 7324.
Silva, J. S. V.; Abdon, M. M. (1998); Delimitação do Pantanal brasileiro e suas sub-regiões. Pesquisas Agropecuárias Brasileiras. v. 33, Brasília, p. 1703-1711. Número Especial.
Tucker, C. J. (1979); Red and photographic infrared linear combinations for monitoring vegetation. Remote Sensing of Environment. n. 8, Elsevier, p. 127-150.
Yuan, H.; Wiele, C. F. V. D; Khorram, S. (2009); An automated artificial neural network system for land use/land cover classification from Landsat TM imagery. Journal of Remote Sensing, 1(3), p. 243-265.