Luís F. A. Guedes, Liliana Vasconcellos, Eduardo Vasconcellosy Moacir Miranda Oliveira Junior
El motor de búsqueda en la Web de Google fue la primera tecnología desarrollada por los fundadores de la empresa, Larry Page y Sergey Brin, cuando aun eran estudiantes en Stanford. Por lo tanto, dicha aplicación ejerce un efecto considerable sobre la curva de aprendizaje. La excelencia de esta tecnología impulsa y apoya la principal fuente de ingresos de la empresa, que es la publicidad online. Un tercio de toda la fuerza laboral de la compañía está involucrado en mejorar los productos, comercializarlos, entrar en contacto con los clientes y controlar los procesos de los productos de publicidad online, principalmente Google AdSense y Google AdWords (Google, 2007).
El balance de 2008 indica que el 97% de los ingresos de 21 mil millones de dólares provenía del negocio de publicidad (Google, 2009b). Sin embargo, Google posee más de doce otros productos, como por ejemplo los famosos Gmail, Google Maps y Google Earth, y otros no tan conocidos, como Google X, Google Code Search y Google Mars. Inclusive especialistas en el mercado de Internet tendrían dificultad para enumerar todos los productos de Google, tal es la conformidad de estos nuevos productos, sea para plataformas ya existentes (Google Desktop Search, Google Scholar y Google Books comparten un núcleo común de software), o para plataformas nuevas (como por ejemplo, Android, el sistema operativo para teléfonos móviles, lanzado en 2008).
Para poder funcionar, los motores de búsqueda a veces deben sobreponerse a administradores de sitio mal intencionados. Dado que la Web cuenta con miles de millones de páginas, el ocupar una posición de relevancia en la página de resultados es esencial para generar buen tráfico. Esto se torna aun más importante en el caso de páginas con publicidad online, o aquellas que ofrecen productos de comercio electrónico. Ha surgido toda una industria que ofrece a los administradores de sitios estrategias y tácticas para mejorar, al menos teóricamente, el desempeño de un sitio Web, en la página de resultados (ya sean páginas de Google, Yahoo! u otros). A este tipo de consultoría se le da el nombre de Optimización de Motor de Búsqueda, o SEO por su sigla en inglés.
Del punto de vista del motor de búsqueda, una vez identificada la lógica que está por detrás del orden de resultados, dichos resultados pueden ser manipulados. Un buen motor de búsqueda en la Web es aquel que no permite la manipulación y está impulsado apenas por la relevancia del contenido. Los ingenieros de Google dedican gran cantidad de recursos para enmascarar la lógica, por detrás del orden de resultados y de los recortes (snippets) de dos líneas que describen cada uno de los resultados de búsqueda, de forma que el resultado sea menos susceptible de manipulación. Las tecnologías básicas de motor de búsqueda de Google son las siguientes: PageRankTM, Cloud computing, emparejamiento de hipertexto (Hypertext matching) y MapReduce. A continuación se detallan algunas de las características de alto nivel de dichas tecnologías.
Por definición, la Web es un conjunto complejo, caótico y creciente de información y contenido. Cuando surgió la Internet, el encontrar una información sencilla requería un método complejo y mucha experiencia. Fue en este contexto que aparecieron los sitios especializados de motores de búsqueda, para ayudar a los usuarios a encontrar lo que buscaban, o por lo menos aproximarlos al resultado de su búsqueda (Poulter, 1997). “A pesar de que existen otras formas de llegar a las páginas de Internet, como por ejemplo, siguiendo enlaces y conociendo o adivinando los localizadores unificados de recursos (URL por su sigla en inglés), los motores de búsqueda representan el principal medio para lograrlo, especialmente para realizar la investigación inicial sobre un asunto en particular” (Introna, Nissenbaum, 2000).
Debido al extraordinario volumen de páginas Web y de contenido en Internet (noticias, videos, fotografías, imágenes, mapas, blogs, redes sociales, etc.) una búsqueda de rutina en la Web aporta una enorme cantidad de resultados (el resultado de la búsqueda por “buena pizza en San Pablo” en Google Brasil retornó 652.000 sitios Web). Por lo tanto, el orden en que dichos resultados aparecen en la página Web es de la más absoluta relevancia, tanto para el usuario (que demanda información precisa), como también para el sitio (que desea atraer la atención hacia su contenido).
El servicio de directorio (colección de páginas similares, indexado manualmente) fue la primera forma de organización del contenido en la Web. Los directorios contenían miles de categorías (como por ejemplo las 590.000 categorías del proyecto llamado ‘Open Directory Project’ – www.dmoz.org) y otros, dedicados a grupos específicos (un ejemplo sería el ‘Medical World Search – www.mwsearch.com). Los motores de búsqueda surgieron, cuando el volumen de contenido en la Web aumentó de manera tan extraordinaria, que los servicios de directorios se hicieron inviables. El primer motor de búsqueda que utilizó índices de páginas Web fue WebCrawler, lanzado en abril de 1994, como parte de un proyecto de investigación de la Universidad de Washington. Más tarde, WebCrawler fue adquirido por InfoSpace.
Los motores de búsqueda utilizan pequeños elementos de software, llamados ‘robots’ o ‘arañas’, cuya tarea es deambular por la Internet, adquiriendo el mayor número posible de páginas Web. Este conjunto de páginas es posteriormente indexado en una enorme base de datos (formada por varios miles de millones de páginas). Los motores de búsqueda normalmente utilizan decenas de robots, que funcionan de forma simultanea, cada uno de ellos capaz de cubrir aproximadamente 50 millones de páginas Web (Cendon, 2001). Como las páginas Web son dinámicas (su contenido cambia a medida que pasa el tiempo), los robots normalmente visitan a su conjunto específico de páginas, una vez al mes, para refrescar la base de datos indexada. En el caso de los sitios más populares de la Web (como por ejemplo, YouTube, Wikipedia y MySpace) se identifican actualizaciones de página y enlaces rotos, prácticamente todos los días. Una vez adquiridas las páginas, los softwares de indización identifican los términos relevantes en cada página y elaboran los índices, utilizados para acelerar el proceso de búsqueda y servir de base para un enfoque del peso de la relevancia. Por ejemplo, si un término en particular aparece de manera consistente en la página Web, o posee cualquier tipo de señal visual, dicho término posee un peso, indicando que en dicha página en particular es posible encontrar información sobre el tema. Si un término no está incluido en el índice, el motor de búsqueda no será capaz de encontrarlo. Por este motivo, la lógica de indización es tan importante para el proceso. La indización y los criterios de atribución de peso tienen gran influencia sobre el desempeño del motor de búsqueda.
La mayoría de los motores de búsqueda coloca en su índice todos los términos relevantes que aparecen en una página Web en particular (excluyendo las preposiciones y demás palabras comunes). Este método crea una enorme base de datos, haciendo que la búsqueda utilice gran nivel de procesamiento. Una posible alternativa es la indización solamente de los términos más relevantes, como por ejemplo, los que se encuentran en el encabezamiento, los que están repetidos varias veces, o aquellos que poseen un tipo de mayor tamaño o algún tipo de señal visual. A pesar de representar una evolución sobre los criterios anteriores, estas innovaciones adicionales no fueron tan eficientes, ya que los algoritmos no realizaban ningún tipo de análisis de contenido o de confiabilidad de las páginas Web. Apenas cuentan y tratan de darle importancia a las palabras. Además, los programadores se aprovechaban fácilmente de la lógica, para mejorar el desempeño de sus sitios en la página de resultados de búsqueda en la Web.
Una de las primeras tareas de Google, cuando aun estaba en su fase de empresa startup, fue el desarrollo de una lógica de búsqueda de página Web y de indización, capaz de ofrecerle a los usuarios un conjunto de respuestas, ponderadas por su relevancia, de acuerdo con las palabras claves de búsqueda. El algoritmo PageRankTM fue el primer paso en este sentido. Una de las principales características de dicho mecanismo es que los criterios de clasificación de respuestas no se ven afectados, ni por la intervención de personas, ni por cualquier tipo de interés comercial. Las respuestas son dadas por un algoritmo, o receta matemática, que combina dos fuentes de información para ponderar la importancia de una página Web específica: una, basada en la relevancia intrínseca del contenido de la página Web, y la otra, basada en la relevancia relativa de la página, entre otras similares. Cada página analizada recibe un coeficiente – el PageRank™ de dicha página Web. Cuanto más alto el coeficiente, más relevante será la página, en general. De acuerdo con Robinson (2004), “el PageRank™ de una página Web mide cuán popular es dicha página, como función de los enlaces de entrada y de salida de la Web.” La idea subyacente al método PageRank™ es que, en la Internet, popularidad significa fiabilidad.
La importancia relativa de una página Web se da mediante una ecuación, que manipula todos los enlaces de entrada y salida de dicha página. Los enlaces de entrada son ponderados por la relevancia de la página que indican (esta relevancia se mide de acuerdo con el PageRank™ de la página Web). Siguiendo esta lógica, cuanto mayor y más relevante sea el número de enlaces que indican una cierta página Web, mayor será la relevancia de dicha página, en lo que se refiere a su contenido. El peso de un enlace de salida se deprecia por el número total de enlaces de salida. A continuación se presenta una forma simplificada de la ecuación de PageRankTM:
![]()
donde:
- PR(a): PageRankTM de la Página Web a
- PR(u): PageRankTM de la Página Web u
- L(u): número de enlaces de salida de la Página u
- Bu: conjunto que contiene todas las páginas con enlaces a la Página u
La Figura 5 presenta un esquema simplificado para ilustrar el PageRank™. El tamaño de cada rectángulo ilustra la importancia de una página Web. Las páginas con más enlaces de entrada poseen un PageRank™ más alto que otras con menor número de enlaces de entrada. Los ‘votos’ de páginas con PageRank™ más alto poseen más relevancia que los ‘votos’ de páginas con PageRank™ más bajo.
Figura 5
Sistema de ‘votación’ ponderada de PageRank
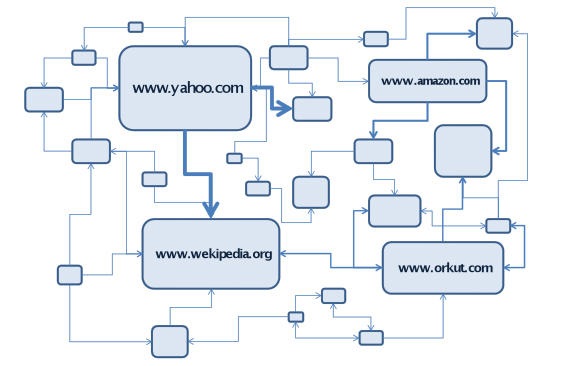
Fuente: autores
A pesar de que el concepto básico es muy claro y sencillo, el volumen de cálculos realizados por Google para determinar el PageRank™ de una página demanda una enorme capacidad computacional, principalmente debido al tamaño gigantesco de la propia Web. El algoritmo de PageRank™ utiliza sofisticadas herramientas matemáticas para realizar todos los cálculos en una única etapa, con el propósito de minimizar el tiempo de ejecución y el impacto del procesamiento (Altman, Tennenholtz, 2005). De hecho, PageRank™ posee muchas otras particularidades que trascienden el alcance del presente estudio.
El identificar las páginas Web más relevantes dentro de un cierto contexto, no significa que dichas páginas representen la mejor respuesta para el usuario. Con el propósito de mejorar la exactitud, Google combina PageRank™ con una sofisticada técnica de emparejamiento de hipertexto, para identificar las páginas que sean, no apenas importantes, sino también relevantes, para una búsqueda en particular (Google, 2009). PageRank™ tiene gran importancia para el motor de búsqueda como un todo, pero no es el único mecanismo utilizado para clasificar resultados. El algoritmo de análisis de emparejamiento de hipertexto utilizado por Google analiza el contenido de cada página Web y recoge cientos de variables para determinar la relevancia de dicha página, de acuerdo con una clave de búsqueda específica, ofrecida por el usuario.
Google considera varias medidas, relacionadas con la presencia de la consulta en la página Web, sin necesariamente darle énfasis específico, ya que el algoritmo de clasificación de relevancia es uno de los principales factores que diferencian a los motores de búsqueda. De acuerdo con Page et. al. (1998), “Google utiliza una serie de factores para ordenar los resultados de la búsqueda, entre los cuales se encuentran medidas IR estándar, proximidad, texto de anclaje (texto de los enlaces que indican páginas Web) y PageRank™. Entre estos elementos, Google incorpora los siguientes, como claves para determinar la relevancia de una página Web de acuerdo con el asunto: tamaño del tipo, color y posición del término aparece en la página Web. Por ejemplo, cuando una página señala dos palabras juntas y que coinciden con una búsqueda de varias palabras, dicha página tendrá más relevancia, que si las palabras se encontraran separadas. Los tipos más grandes también indican mayor relevancia que los más chicos y elementos señalados con diferentes colores, o que aparecen antes en el sitio, probablemente serán más importantes, que un texto en blanco y negro, o que aparezca más adelante en la página (Google, 2009; Page et. al. 1998; Cho et. al. 1998).
El concepto subyacente de Cloud Computing data de 1960 y fue mencionado, por primera vez, por el especialista en computación, John McCarthy. Él sugirió que Cloud Computing podría algún día transformarse en un servicio de utilidad pública, como por ejemplo, los servicios de agua o electricidad (Buyya et. al. 2007). Seria un escenario equivalente al de la evolución en los servicios de electricidad cien años atrás, época en que los agricultores desconectaron sus generadores y comenzaron a comprar la electricidad generada por plantas industriales, mucho más eficientes. Sin embargo, como lo demuestra la siguiente figura, el antiguo concepto, o sea el interés en Cloud Computing, ha resurgido recientemente.
Figura 6
Interés creciente por Cloud Computing
Fuente: autores (datos brutos obtenidos de Google Trends)
Actualmente, Cloud Computing puede definirse como una infraestructura formada por dos elementos: una enorme plataforma de hardware, que incluye un conjunto de computadores interconectados, y una compleja aplicación de software que administra dichos recursos. La Nube de Google, por ejemplo, es una red formada por cientos de miles de servidores sencillos, interconectados, cada uno de los cuales posee aproximadamente la capacidad de un PC estándar. La Nube de Google almacena un extraordinario volumen de datos, incluyendo copias de la World Wide Web entera, y posee la capacidad agregada de un enorme supercomputador. Este conjunto de hardware le permite a Google responder a los varios millones de consultas diarias, en una fracción de segundo, y le permite también, utilizar algoritmos de búsqueda y recuperación que demandan alta capacidad computacional (Google, 2007). La opción de Google de invertir en hardware tuvo como resultado un desarrollo de competencia que representa una importante ventaja competitiva, comparado con otras empresas de Internet (Stross, 2008).
Sin embargo, una Nube es más que un conjunto de recursos computacionales, ya que posee un mecanismo para administrar sus propios recursos. Una plataforma de hardware de Cloud Computing puede ser programada para recibir nuevas solicitudes de aprovisionamiento, reconfigurar los sistemas, reequilibrar la carga de trabajo y realizar el monitoreo de errores y desempeño. A continuación se muestra un esquema sencillo de Cloud Computing.
Figura 7
Arquitectura Simplificada de Cloud Computing
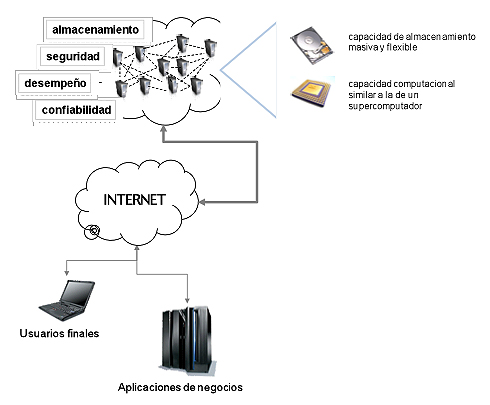
Fuente: autores
La Figura 7 demuestra que, al igual que los usuarios de negocios, los demás tipos de usuarios pueden tener acceso a archivos y utilizar softwares que no están físicamente en sus computadores. Los archivos y softwares se encuentran en la Nube, distribuidos entre varios servidores, normalmente en varios lugares. Por motivos estratégicos, Google no divulga la localización o el volumen de su centro de datos, pero se da por cierto que se encuentran divididos entre diferentes locales y que operan en un esquema de redundancia.
Cloud Computing también describe un conjunto de aplicaciones desarrolladas para el acceso de usuarios en todo el mundo, a través de la Internet. Dichas aplicaciones en Nube utilizan grandes centros de datos y servidores con gran capacidad, que hospedan aplicaciones y servicios Web. Cualquier persona que cuente con una conexión adecuada de Internet y un navegador estándar puede tener acceso a una aplicación en Nube (Chapel, 2008).
Google comenzó a utilizar Cloud Computing desde la fundación de la empresa. En aquella época, el principal motivo era implementar un diseño de hardware de bajo costo, que ejecutara una tarea con alta demanda computacional, en pocos segundos. Los fundadores de Google crearon sus propios servidores, con piezas de bajo costo, destinadas a computadores de uso personal. La intención era ahorrar dinero. Al mismo tiempo, observaron que una red de computadores seria mucho más eficiente para la Web que las otras alternativas disponibles (Hansell, Markoff, 2006). Actualmente, la Nube de Google posee las mismas características que el resto de los esquemas de Nube, entre las cuales se destaca el hecho de nunca caducar. Cuando un servidor deja de funcionar o sufre daños, el personal de mantenimiento lo retira y lo sustituye por otro nuevo, más moderno y veloz. De esta forma, la Nube se regenera a la medida que crece y prácticamente nunca queda inoperante. En conjunto, los miles de equipos de Google forman un supercomputador de gran volumen y eficiencia, del punto de vista de costo, optimizado para ejecutar una tarea de gran magnitud, o sea, encontrar, seleccionar y extraer información de la Web, de la forma más rápida y exacta posible (Google, 2009).
Dadas estas características, el uso de Cloud Computing le ofrece a Google una enorme capacidad de procesamiento (una búsqueda normal lleva menos de 0,5 segundos), la oportunidad de realizar negocios (arrendando su capacidad y poder de procesamiento) y una forma de acelerar el desarrollo de nuevos productos (por medio de un ambiente único para realizar simulaciones).
Cuando un usuario teclea una consulta, los términos de la búsqueda se consultan en un índice y los resultados surgen a partir de un conjunto separado de servidores (que ofrecen recortes, o snippets, de páginas que coinciden y se originan en las copias que Google posee de la Web). Al mismo tiempo, surgen los anuncios relacionados que, a su vez, provienen de otro conjunto de servidores. Para mejorar el alto desempeño que el negocio demanda, Google utiliza un software estratégico, desarrollado internamente, llamado MapReduce. Se trata de un modelo de programación, creado a principios del año 2003, para el uso de grandes sistemas distribuidos. El software clasifica la información clave por categorías y la distribuye, a través de su centro o ‘farm’ de servidores de PCs, para posteriormente eliminar los datos considerados irrelevantes. MapReduce divide cada una de las tareas complejas, en pequeñas tareas, y las ejecuta de forma simultánea, en miles de computadores en la Nube. En una fracción de segundo, cada uno de los computadores devuelve su contribución específica y MapReduce rápidamente consolida los datos (Dean, Ghemawat, 2004; Stibel, 2008).
A continuación, con el auxilio de PageRank™ y del análisis de emparejamiento de hipertexto, se monta la página de resultados de búsqueda. Google logra ejecutar esta tarea de alta complejidad, con bajo costo y en menos de un segundo, por medio de computadores creados a partir de componentes off-the-shelf, de bajo costo e interconectados de forma veloz y segura, utilizando su propio software (Google, 2009).
MapReduce le permite a Google crear un programa y operarlo con eficiencia en miles de computadores, lo cual acelera el ciclo de desarrollo y de prototipo. MapReduce fue diseñado para auxiliar a los programadores que no poseen experiencia en sistemas distribuidos de gran escala “pues oculta los detalles de paralilización, tolerancia de fallas, optimización de posición y equilibrio de carga” (Dean, Ghemawat, 2004).
Google utiliza MapReduce para un amplio rango de aplicaciones (Google, 2009c):
[anterior] [inicio] [siguiente]
Vol. 31 (1) 2010
[Índice]